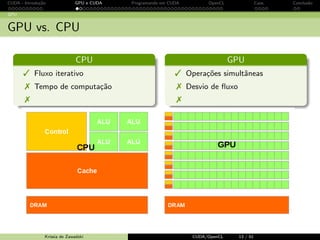
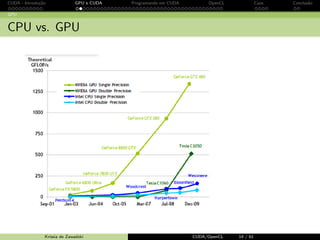
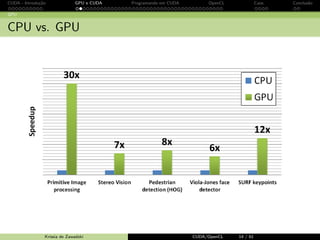
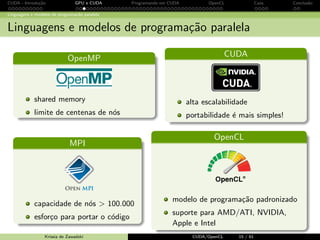
Baixado 20 vezes











![o ECC2K-130
diretamente em codigo de maquina.
BERNSTEIN, D. J. et al. Usable Assembly Language for GPUs: A
Success Story. In: Workshop Records of Special-Purpose Hardware
for Attacking Cryptographic Systems – SHARCS 2012. [s.n.], 2012.
p. 169–178.
Compilador NVCC muito lento para lidar com kernels contendo
muitas instruc~oes.
Registradores alocados de forma pouco e](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-39-320.jpg)
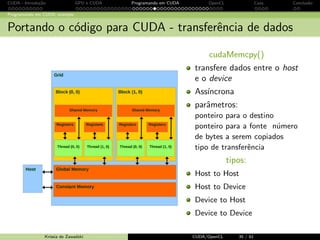

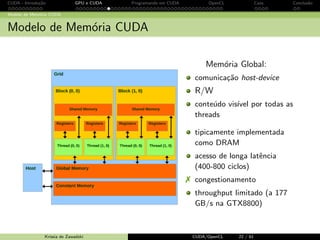
![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
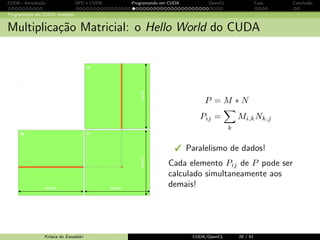
Programando em CUDA: exemplo
Fun¸c˜ao C sequencial (host)
void MatMul ( float *M; float *N, float *P, int Width )
{
for ( int i = 0; i Width ; ++i)
for (int j = 0; j Width ; ++j){
float sum = 0;
for ( int k = 0; k Width ; ++k){
float m = M[i* Width + k];
float n = N[k* width + j];
sum += m * n;
}
P[i * Width + j] = sum ;
}
}
Krissia de Zawadzki CUDA/OpenCL 32 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-44-320.jpg)

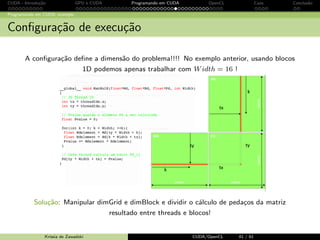

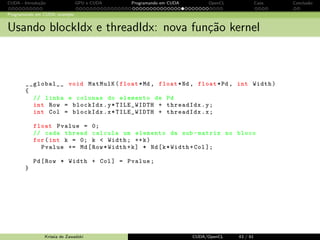


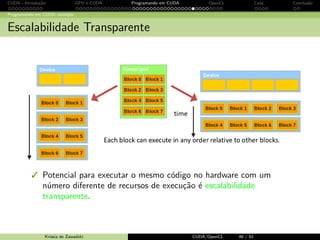
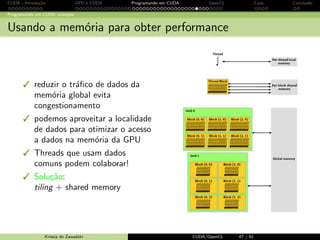
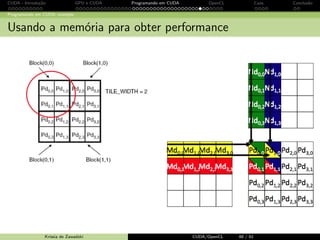

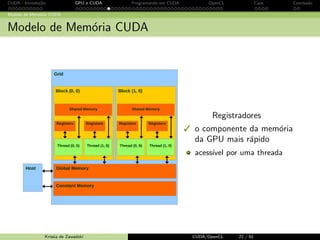
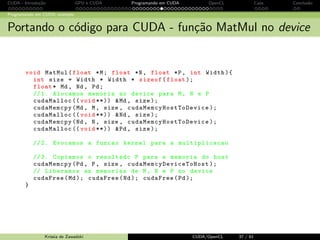
![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
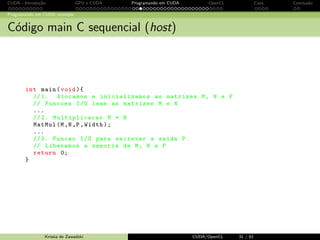
Programando em CUDA: exemplo
Usando blockIdx e threadIdx: nova fun¸c˜ao kernel
__global__ void MatMulK ( float *Md , float *Nd , float *Pd , int Width )
{
// linha e colunas do elemento de Pd
int Row = blockIdx .y* TILE_WIDTH + threadIdx .y;
int Col = blockIdx .x* TILE_WIDTH + threadIdx .x;
float Pvalue = 0;
// cada thread calcula um elemento da sub - matriz no bloco
for ( int k = 0; k Width ; ++k)
Pvalue += Md[ Row * Width +k] * Nd[k* Width +Col ];
Pd[ Row * Width + Col ] = Pvalue ;
}
Krissia de Zawadzki CUDA/OpenCL 43 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-57-320.jpg)

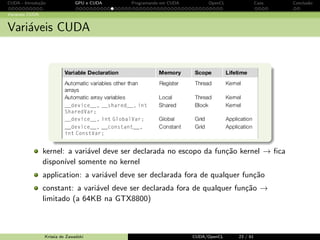
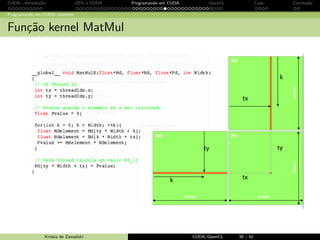
![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
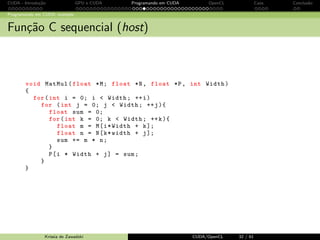
Programando em CUDA: exemplo
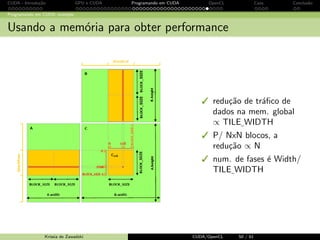
Kernel MatMul com mem´oria compartilhada
__global__ voidMatMulK ( float *Md , float *Nd , float *Pd , int Width )
{
__shared__ float Mds [ TILE_WIDTH ][ TILE_WIDTH ];
__shared__ float Nds [ TILE_WIDTH ][ TILE_WIDTH ];
int bx = blockIdx .x; int by = blockIdx .y;
int tx = threadIdx .x; int ty = threadIdx .y;
// Identificamos a linha e a coluna do elemento de Pd
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
// Loop sobre os tiles Nd e Md
for ( int m = 0; m Width / TILE_WIDTH ; ++){
Mds [ty ][ tx] = Md[Row * Width + (m* TILE_WIDTH + tx )];
Nds [ty ][ tx] = Nd [(m+ TILE_WIDTH + ty )* Width + Col ];
_syncthreads ();
for ( int k = 0; k TILE_WIDTH ; ++k)
Pvalue += Mds [ty ][k] * Nds[k][ tx]
_syncthreads ();
}
Pd[ Row * Width + Col ] = Pvalue ;
}
Krissia de Zawadzki CUDA/OpenCL 51 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-68-320.jpg)

![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
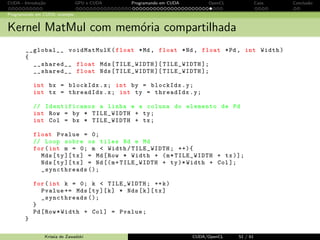
OpenCL e CUDA
OpenCL e CUDA
OpenCL API call Explica¸c˜ao equivalente em CUDA
get global id(0); ´ındice global do work item blockIdx.x ×blocDim.x + threadIdx.x
get local id(0); ´ındice local do work group threadIdx.x
get global size(0); tamanho do range ND gridDim.x ×blocDim.x
get local size(0); tamanho de cada work group blockDim.x
OpenCL conceito de paralelismo equivalente em CUDA
Kernel Kernel
programa Host programa Host
ND range (espa¸co de ´ındice) Grid
work item Thread
work group Block
__kernel void vadd ( __global const float *a, __global const float *b,
__global float * result ){
int id = get_global_id (0) ;
result [id] = a[id ]+b[id ];
}
Krissia de Zawadzki CUDA/OpenCL 54 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-71-320.jpg)
![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
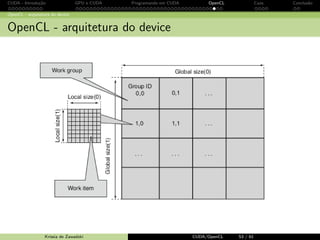
Exemplo de c´odigo OpenCL: multiplica¸c˜ao matricial
Exemplo de c´odigo OpenCL: multiplica¸c˜ao matricial
# define BLOCK_SIZE 16
__kernel void
matrixMul ( __global float * P, __global float * M, __global float * N, int Width )
{
int bx = get_group_id (0) , by = get_group_id (1);
int tx = get_local_id (0) , ty = get_local_id (1);
int mBegin = Width * BLOCK_SIZE * by;
int mEnd = aBegin + Width - 1;
int mStep = BLOCK_SIZE ;
int nBegin = BLOCK_SIZE * bx;
int nStep = BLOCK_SIZE * Width ;
for (int m = mBegin , n = nBegin ; m = mEnd ; m += mStep , n += nStep )
{
__local float Ms[ BLOCK_SIZE ][ BLOCK_SIZE ];
__local float Ns[ BLOCK_SIZE ][ BLOCK_SIZE ];
Ms[ty ][ tx] = M[m + Width * ty + tx ];
Ns[ty ][ tx] = N[n + Width * ty + tx ];
barrier ( CLK_LOCAL_MEM_FENCE );
for (int k = 0; k BLOCK_SIZE ; ++k)
Psub += Ms[ty ][k] * Ns[k][ tx ];
barrier ( CLK_LOCAL_MEM_FENCE );
}
int p = Width * BLOCK_SIZE * by + BLOCK_SIZE * bx;
P[p + Width * ty + tx] = Psub ;
}
Krissia de Zawadzki CUDA/OpenCL 55 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-72-320.jpg)

![CUDA - Introdu¸c˜ao GPU e CUDA Programando em CUDA OpenCL Caos Conclus˜ao
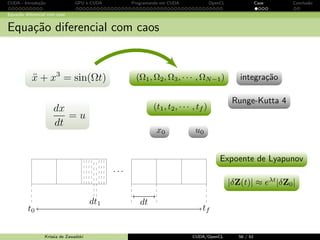
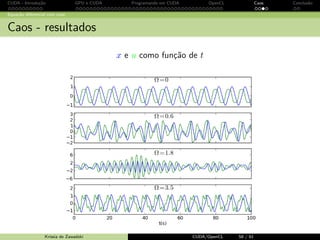
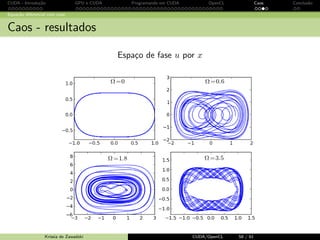
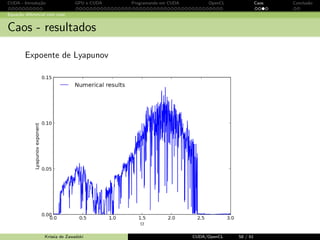
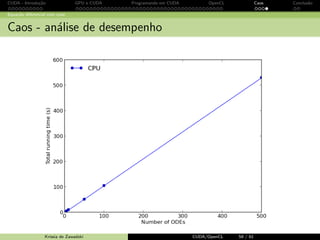
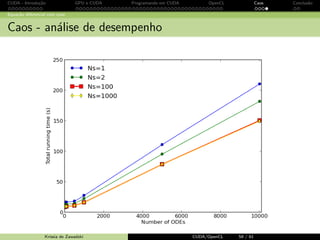
Equa¸c˜ao diferencial com caos
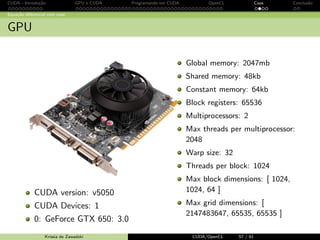
GPU
CUDA version: v5050
CUDA Devices: 1
0: GeForce GTX 650: 3.0
Global memory: 2047mb
Shared memory: 48kb
Constant memory: 64kb
Block registers: 65536
Multiprocessors: 2
Max threads per multiprocessor:
2048
Warp size: 32
Threads per block: 1024
Max block dimensions: [ 1024,
1024, 64 ]
Max grid dimensions: [
2147483647, 65535, 65535 ]
Krissia de Zawadzki CUDA/OpenCL 57 / 61](https://image.slidesharecdn.com/02zgjkfkqrecja0wbg4k-signature-abbb5e1aea1218204ee0368cf52bccd61cb044249239c3076e27bce858dfa0ba-poli-141001154434-phpapp01/85/CUDA-Open-CL-74-320.jpg)





O documento discute arquiteturas de computação paralela avançadas como CUDA e OpenCL. Explica o que é CUDA, sua história, arquitetura de GPU, modelo de memória e programação. Também aborda OpenCL e aplicações dessas tecnologias em ciência de dados e computação científica.












































