Este documento apresenta o quarto volume de um curso sobre banco de dados. O capítulo 10 discute a álgebra relacional e o cálculo relacional, linguagens formais para manipulação de dados em bancos de dados relacionais. O capítulo descreve operadores de conjuntos e operadores de tabelas da álgebra relacional, incluindo união, interseção, diferença e produto cartesiano. O capítulo 11 abordará a linguagem SQL para criação e manutenção de bancos de dados. O capítulo 12 tratará de consultas básicas e














![Banco de Dados
t, tal que o predicado P seja verdadeiro para t. E temos que t é uma variável de tuplas. P é
uma expressão condicional e t.A ou t[A] denota o valor do atributo A da tupla t. O resultado
de tal consulta é o conjunto de todas as variáveis tuplas para as quais o predicado é indicado
como verdadeiro.
Uma expressão genérica do cálculo relacional de tuplas tem a forma:
{t1.A1, t2.A2, ..., tn.An | predicado(t1, t2, ..., tn, tn+1, tn+2, ..., tn+m)}
Onde: t1, t2, ..., tn, tn+1, tn+2, ..., tn+m são variáveis de tuplas, cada Ai é um
atributo da relação na qual ti se encontra e o predicado é uma fórmula do cálculo relacional
de tuplas.
Uma fórmula é definida, de forma recursiva, por uma ou mais fórmulas atômicas.
Essas fórmulas podem ser conectadas por operadores lógicos (AND, OR ou NOT), como
segue:
» Se F1 e F2 são fórmulas atômicas, então (F1 AND F2), (F1 OR F2), NOT (F1) e NOT
(F2) também o são, tendo seus valores verdade derivados a partir de F1 e F2.
Relembrando...
(F1 AND F2) será TRUE apenas se ambos, F1 e F2, forem TRUE;
(F1 OR F2) será TRUE quando uma das duas fórmulas F1 e F2, for TRUE;
NOT(F1) será TRUE quando F1 for FALSE;
NOT(F2) será TRUE quando F2 for FALSE.
» Se F1 é uma fórmula atômica, então (Ǝ t)(F1) também o é, e seu valor verdade
apenas será TRUE se a fórmula F for avaliada como verdadeira para pelo menos
uma tupla atribuída para ocorrências livres de t (que é uma variável de tupla) em F.
» Se F1 é uma fórmula atômica, então (∀ t)(F1) também o é, e seu valor verdade
apenas será TRUE se a fórmula F for avaliada como verdadeira para todas as tuplas
atribuídas para ocorrências livres de t em F.
Adicionalmente, temos:
» Uma fórmula atômica ti.A op tj.B, onde op é um dos operadores de comparação no
conjunto {=, >, <, ≠, >=, <=}, ti e tj são variáveis de tuplas, A é um atributo da relação
na qual ti se encontra, B é um atributo da relação na qual tj se encontra.
» Uma fórmula atômica ti.A op c ou c op tj.B, onde op é um dos operadores de
comparação no conjunto {=, >, <, ≠, >=, <=}, ti e tj são variáveis de tuplas, A é um
atributo da relação na qual ti se encontra, B é um atributo da relação na qual tj se
encontra e c é um valor constante.
Nos dois casos acima, se as variáveis de tupla forem designadas de forma que
os valores dos atributos especificados satisfaçam o predicado, a fórmula assumirá valor
verdade TRUE.
Cada uma das fórmulas atômicas anteriormente especificadas tem seu valor
verdade avaliado como TRUE ou FALSE para uma combinação específica de tuplas.
17](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-17-320.jpg)










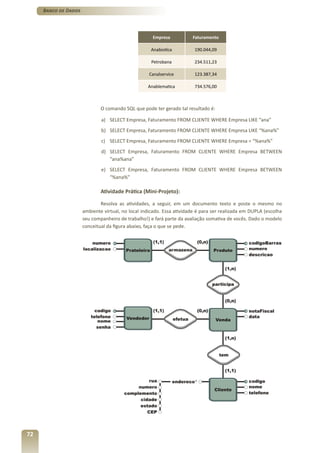
![Banco de Dados
AUTOR (CodAutor (PK), Nome, Nascimento)
LIVRO (TitLivro (PK), CodAutor (FK), CodEditora (FK), Valor,Publicacao, Volume,
Idioma)
EDITORA (CodEditora (PK), Razao, Endereco, Cidade)
DDL - Criando Tabelas
O comando CREATE TABLE especifica uma nova tabela (relação), dando o seu nome
e especificando as colunas (atributos), cada uma com seu nome, tipo e restrições iniciais.
A forma geral do comando é: create table nome_tabela. Por exemplo: create table
Empregado. Porém, a sintaxe completa do comando é bem mais detalhada:
CREATE TABLE Nome_Tabela (
Nome_Atributo1 Tipo [(Tamanho)] [NOT NULL] [DEFAULT valor] [...],
[,Nome_Atributo2 Tipo [(Tamanho)] [NOT NULL] [DEFAULT valor] [...],
[PRIMARY KEY (Primária1[, Primária2 [, ...]])]
[UNIQUE (Candidata1[, Candidata2[, ...]])]
[FOREIGN KEY (Estrangeira1[, Estrangeira2 [, ...]]) REFERENCES
TabelaExterna [(AtributoExterno1 [, AtributoExterno2 [, ...]])]
[CHECK (condição)]
)
Onde : ( ) Indica parte da sintaxe do comando e [ ] Indica opcionalidade do comando.
Vamos explicar agora cada parte do comando completo.
Nome_Atributo - nome do atributo que está sendo definido
Tipo: domínio do atributo ou seja o tipo do dado do atributo.
Tamanho : alguns tipos de dados necessitam de especificação do tamanho do dado.
Por exemplo, o tipo CHAR
NOT NULL: expressa que o atributo não pode receber valores nulos
DEFAULT valor: indica um valor a ser atribuído ao atributo caso não seja
determinado um valor durante a inserção
PRIMARY KEY (Primária1, Primária2, ...) – serve para especificar a(s) chave(s)
primária(s) da tabela.
UNIQUE: indica que o atributo tem valor único na tabela. Qualquer tentativa de se
introduzir uma linha na tabela contendo um valor igual ao do atributo será rejeitada. Serve
para indicar chaves secundárias (chaves candidatas). Em Candidata1, Candidata2 devem ser
especificados os atributos que terão esse valor único na tabela.
FOREIGN KEY (Estrangeira1[, Estrangeira2 [, ...]]) REFERENCES TabelaExterna
[(AtributoExterno1 [, AtributoExterno2 [, ...]]) – serve para especificar os atributos que
são chaves estrangeiras na relação, já relacionando-os às tabelas onde eles são chave
primária (Integridade Referencial). Em Estrangeira1, Estrangeira2, ... especificam-se os
atributos que são chave estrangeira. Em TabelaExterna se especifica o nome da tabela onde
o atributo é chave primária e, por fim, o nome desse atributo nessa TabelaExterna (porque
os atributos na relação e na tabela externa original podem ter nomes diferentes). Se os
atributos da relação e da tabela externa tiverem o mesmo nome, esses AtributoExterno1,
29](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-29-320.jpg)

![Banco de Dados
PRIMARY KEY (matricula),
CHECK (nivel IN (“Bacharelado”, ”Mestrado”, ”Doutorado”)))11
O SQL-89 obrigava os atributos da chave primária a serem declarados como NOT NULL e UNIQUE. Comentário
SQL-92 e posteriores já assumem essas condições, assim, sua declaração é redundante.
10
Aqui é especificado
Uma cláusula FOREIGN KEY pode incluir regras de remoção / atualização: que os livros que
forem criados devem
FOREIGN KEY (coluna) REFERENCES tabela ter seu valor maior
que 10. Essa é uma
[ON DELETE {RESTRICT | CASCADE | SET NULL | SET DEFAULT}] validação que será
feita a cada inserção /
[ON UPDATE {RESTRICT | CASCADE | SET NULL | SET DEFAULT}]
alteração de dados na
Suponha que T2 tem uma chave estrangeira para T1, ou seja, tem um atributo que tabela.
é chave primária em T1. Vejamos as cláusulas ON DELETE e ON UPDATE
ON DELETE Comentário
RESTRICT: (default) significa que uma tentativa de se remover uma linha de T1 11
Veja que aqui
falhará se alguma linha em T2 combinar com a chave da tupla de T1 que está sendo estamos especificando
deletada. os valores possíveis
para o atributo nível.
CASCADE: a remoção de uma linha de T1 implica em remoção de todas as linhas de
T2 que combinam com a chave da tupla de T1 sendo deletada.
Comentário
SET NULL: remoção de T1 implica em colocar NULL em todos os atributos de T2 que
sejam chave estrangeira e estejam relacionados com a tupla sendo deletada em T1.
12
O valor default para
SET DEFAULT: remoção de linha em T1 implica em colocar valores DEFAULT nos o departamento é 1.
atributos da chave estrangeira de cada linha de T2 que combina
ON UPDATE Comentário
RESTRICT: (default) a atualização de um atributo de T1 falha se existem linhas em
T2 combinando com a tupla sendo modificada. A chave primária é a
13
matrícula.
CASCADE: a atualização de atributo em T1 implica que linhas que combinam em T2
também serão atualizadas
Comentário
SET NULL: a atualização de T1 implica que valores da chave estrangeira em T2, nas
linhas que combinam com a tupla de T1 sendo atualizada, são postos para NULL. 14
Veja que aqui o
atributo da tabela
SET DEFAULT: a atualização de T1 implica que valores da chave estrangeira de T2 sendo definida tem
nas linhas que combinam terão valores default aplicados. nome diferente do
atributo na sua tabela
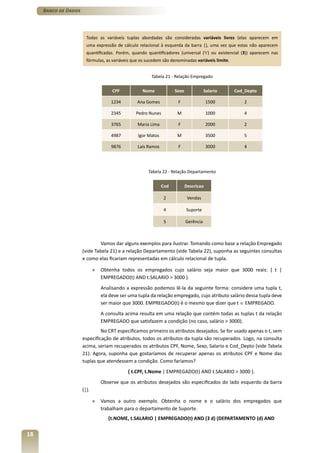
Vamos dar um exemplo de uso dessas cláusulas: externa de origem.
Por isso, o nome do
CREATE TABLE empregado (
atributo na tabela
matricula char(10) NOT NULL, externa precisa ser
especificado.
nome char(15) NOT NULL,
cod_depto INT NOT NULL DEFAULT 112, Comentário
PRIMARY KEY(matricula) , 13
15
Aqui é especificado
FOREIGN KEY(supervisor) REFERENCES Empregado(matricula)14
que, se a tupla que
ON DELETE SET NULL15 contém a matrícula
sendo utilizada nesta
ON UPDATE CASCADE16, tabela for deletada, o
atributo SUPERVISOR
FOREIGN KEY (cod_depto) REFERENCES Departamento(codigo) deverá receber o valor
NULL.
ON DELETE SET DEFAULT17
31](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-31-320.jpg)
![Banco de Dados
ON UPDATE CASCADE);
DDL - Alterando Tabelas
O comando ALTER TABLE permite inserir/eliminar/modificar colunas nas tabelas já
existentes, modificando a estrutura das mesmas. A sintaxe básica desse comando é:
ALTER TABLE Tabela {
ADD (NomeNovoAtributo NovoTipo [BEFORE Nome_Atributo] [, ...] ) |
Comentário
DROP (Nome_Atributo [, ...] ) |
16
Aqui é especifricado MODIFY ( Nome_Atributo NovoTipo [ NOT NULL ] [DEFAULT, ... ] )
que, se a matrícula for
atualizada na tabela }
de origem, todas as Onde: | Indica escolha de várias opções e { } Indica obrigatoriedade de escolha de
tuplas da tabela onde
o atributo é chave uma opção entre as várias. Agora, vamos explicar cada parte do comando.
estrangeira devem ser
atualizadas também. Adicionando um novo atributo (nova coluna) na Tabela
ADD (NomeNovoAtributo NovoTipo [BEFORE Nome_Atributo] [, ...] ) |
Usando o ADD é possível adicionar um novo atributo na Tabela. Dessa forma, o novo
Comentário atributo deve ser especificado (nome e tipo). É possível ainda dizer antes de qual atributo
se deseja que esse novo atributo seja inserido (BEFORE nome_atributo). Por exemplo, se
17
Aqui é especificado desejássemos adicionar o campo E-MAIL na tabela Autor, do nosso exemplo base (Figura 4),
que, se a tupla que usaríamos:
contém o código do
departamento sendo ALTER TABLE AUTOR ADD EMAIL CHAR(40);
utilizado nesta tabela
for deletada, o atributo
cod_depto deverá
receber o valor default
especificado para este Observação
atributo. No caso, o
número 1.
Os novos atributos terão valores nulos em todas as linhas. Por isso, não se pode usar NOT NULL
juntamente com ADD (na definição do novo atributo), quando a tabela já contiver registros
(lembre, com o uso de ADD a nova coluna é carregada com NULL’s).
Deletando um atributo (uma coluna) da Tabela
DROP (Nome_Atributo [, ...] ) |
Para usar a cláusula DROP é necessário apenas especificar o nome do atributo que
se deseja remover da tabela. Porém, atenção, a cláusula DROP não remove atributos da
chave primária. Por exemplo, se desejássemos eliminar o campo E-MAIL (anteriormente
adicionado) da tabela Autor, usaríamos:
ALTER TABLE AUTOR DROP EMAIL;
A cláusula DROP pode ser usada com algumas configurações adicionais:
DROP Nome_Atributo [CASCADE | RESTRICT] onde:
CASCADE: removeria o atributo de todos os lugares onde ele estivesse sendo usado
(outras tabelas como chave estrangeira e em visões).
RESTRICT: não permitiria a remoção do atributo se este estivesse sendo usado em
uma visão ou como chave estrangeira em outra tabela.
32](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-32-320.jpg)
![Banco de Dados
Ex: ALTER TABLE AUTOR DROP EMAIL RESTRICT;
Modificando um atributo (uma coluna) da Tabela
Comentário
MODIFY18 ( Nome_Atributo NovoTipo [ NOT NULL ] [, ... ] )
Esta cláusula serve para modificar as informações de um atributo como, por
18
Em alguns SGBDs
ao invés de MODIFY
exemplo, seu tamanho, sua nulidade, etc. Quando se altera o tipo de dados de uma coluna,
é usada a cláusula
os dados são convertidos para o novo tipo. Por exemplo, se desejássemos modificar o ALTER.
campo E-MAIL na tabela Autor, diminuindo seu tamanho de 40 para 30, usaríamos:
ALTER TABLE AUTOR MODIFY EMAIL CHAR(25);
O detalhe é que, se se diminuir o tamanho de um atributo do tipo CHAR, os dados
existentes serão truncados, havendo assim, perda de informação.
DDL – Criando e Removendo Índices
Índices são estruturas que permitem agilizar a busca e ordenação de dados em
tabelas. Para criar um índice em uma tabela existente usamos o comando CREATE INDEX. A
sintaxe completa desse comando é:
CREATE [UNIQUE] INDEX Nome_Indice ON
Nome_Tabela (Nome_Atributo1 [, Nome_Atributo2…])
Neste comando devemos especificar se o índice deve ser único (UNIQUE), ou seja,
não deve permitir repetições (restrição de chaves) ou se será apenas um índice usado para
acelerar a busca entre as tuplas da tabela. Depois, devemos especificar o nome do índice
(Nome_Indice), a qual tabela ele vai pertencer (Nome_Tabela) e qual(ais) atributo(s) fará Comentário
(ão) parte do índice. Por exemplo, se desejássemos criar um índice para o campo código do
autor da tabela Autor, usaríamos: 19
Foi usado o sufixo
IDX para indicar que
CREATE UNIQUE INDEX CodigoIDX ON Autor (CodAutor);
19
é um índice para o
Agora, se desejássemos criar um índice para pesquisar pelo código do autor e pelo código do autor.
código da editora ao mesmo tempo, usaríamos:
CREATE INDEX AutorEditoraIDX ON Livro (CodAutor,CodEditora);
O default é indexar em ordem ascendente, se quisermos uma ordem descendente Comentário
devemos adicionar palavra DESC depois do nome do atributo (no final do comando). Por
exemplo, suponha que se deseja pesquisar os autores pelo seu nascimento. Mas das datas 20
Foi usado o sufixo
maiores (mais rescentes) para as menores (mais antigas). Assim, ficaríamos com: IDX para indicar que é
um índice para o nome
CREATE INDEX NascIDX20 ON Autor (Nascimento) DESC; do autor.
Observação
Uma consulta que envolva atributos indexados é realizada com um tempo de execução melhor
do que com atributos não-indexados. Agora, cuidado, você também não pode indexar TODOS os
atributos de uma tabela. Você deverá usar o bom-senso para escolher quais aqueles que serão
indexados de acordo com o problema sendo modelado e a freqüência de uso do atributo em
consultas.
Alguns SGBDs (por exemplo, o Oracle) criam, automaticamente, índices para as
chaves primárias das tabelas, fazendo uso da cláusula UNIQUE.
33](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-33-320.jpg)





![Banco de Dados
Capítulo 12 – Consultas em Banco de
Dados Relacionais
Vamos conversar sobre o assunto?
No capítulo anterior você aprendeu como criar fisicamente o seu banco de dados
através dos comandos da DDL (Data Definition Language) da SQL. Ou seja, você aprendeu
como fazer a criação de tabelas, índices para determinados atributos das tabelas e fazer a
manutenção de tudo que foi criado em termos de esquema (definição da tabela). Agora, que
as tabelas já estão criadas, resta saber como inserir dados nas mesmas, como atualizar ou
deletar esses dados inseridos, além de como fazer para buscar informações em uma ou mais
tabelas através de consultas simples ou aninhadas. É justamente isto que você irá estudar
neste capítulo.
Neste capítulo estudaremos a DML (Data Manipulation Language) da SQL que
engloba justamente os comandos da SQL para inserção, deleção, atualização e consulta de
dados em tabelas de banco de dados relacionais. Vamos lá?
Inserindo Dados em Tabelas
A partir do momento em que uma tabela está criada, ela já pode receber a entrada
de dados. Para isto usamos o comando INSERT INTO. Este comando adiciona uma ou mais
linhas na tabela. A sintaxe desse comando é:
è Para inserir uma única tupla (linha):
INSERT INTO nome_tabela [(atrib1,atrib2,...)] VALUES (valor1, valor2,...)
Onde:
nome_tabela deve ser o nome da tabela onde se deseja inserir dados.
Atrib1, atrib2, ... são os nomes dos atributos que receberão os valores na inserção.
Se for omitida essa lista de nomes de atributos serão selecionadas todas as colunas
da tabela, pela sua ordem de criação33. Se for especificada uma lista de nomes
de atributos, os valores para os dados deverão ser especificados para inserção na Comentário
ordem em que aparecem na lista.
Valor1, valor2, ... são os valores que serão atribuídos aos atributos. Esses valores 33
Importante atentar
devem ser especificados seguindo a ordem dos atributos (ou da lista de atributos para isto porque você
deverá especificar
especificada no comando ou a ordem de criação dos atributos na tabela). Na os valores a serem
especificação dos valores também deve-se atentar que: 1) Valores de atributos do inseridos também pela
tipo caracter (CHAR ou VARCHAR) e do tipo DATE devem estar entre apóstrofos. ordem de criação dos
atributos. Senão, corre
2) A entrada de dados baseada em caracteres deve ser efetuada, de preferência
o risco de inserir dados
com caracteres em maiúsculo e sem acentuação, pois se algum acento for utilizado, nos campos errados.
pode criar problemas no momento de uma pesquisa com uma palavra idêntica que
não possua acento. 3) Os atributos especificados como NOT NULL devem sempre
receber algum valor senão um erro será gerado e o comando não será executado,
39](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-39-320.jpg)
![Banco de Dados
pois esses atributos nunca poderão ficar vazios.
Comentário è Para inserir mais de uma tupla (linha):
INSERT INTO nome_tabela [(atrib1,atrib2,...)] <comando SELECT>34
34
O comando SELECT
sera explicado Vamos exemplificar o uso desses comandos. Para isso, tomaremos como base o
posteriormente. Por modelo relacional usado nos exemplos do capítulo anterior, mas com alguns atributos a
hora, o importante é
menos, veja:
saber que podemos
inserir em uma tabela,
várias tuplas, resultado AUTOR (CodAutor (PK), Nome, Nascimento)
de uma consulta
usando SELECT.
LIVRO (TitLivro (PK), CodAutor (FK), CodEditora (FK), Valor, Ano_Publicacao)
EDITORA (CodEditora (PK), Razao, Endereco, Cidade)
Vamos aos exemplos. Suponha que você deseje inserir um registro na tabela Autor.
Comentário
Como ficaria?
35
Observe que, como INSERT INTO Autor ( CodAutor, Nome, Nascimento )
mencionado, valores
do tipo caracter e VALUES (112, ‘C. J. Date’, ‘03/12/1941’35);
valores do tipo DATE
Lembrando que a ordem dos valores deve ser a mesma ordem dos atributos para
devem vir entre
apóstrofos. que sejam inseridos nos lugares corretos. Agora, vamos inserir um registro na tabela Editora.
INSERT INTO Editora( CodEditora, Razao, Endereco, Cidade )
VALUES (1, ‘Editora Campus’, ‘R. Sete de Setembro,111’, ‘Rio de Janeiro’);
Depois de preenchida as tabelas base (que não dependem de nenhuma outra),
Comentário
vamos colocar um registro na tabela Livro, que depende de valores cadastrados nas duas
tabelas anteriores
36
Lembre que, quando
não especificamos a INSERT INTO Livro36
ordem dos atributos,
é tomada a ordem de VALUES (‘Introdução a Sistemas de Banco de Dados’, 11237, 138, NULL39, ‘2000’);
criação dos atributos
na tabela. Assim, os Chamamos a atenção para o fato que, na Tabela Livro, o código do autor e o código
valores dos atributos da editora são chaves estrangeiras e, para que tudo dê certo, os valores utilizados, aqui, no
deveriam vir nessa
insert, devem existir anteriormente nas tabelas de origem das chaves estrangeiras, no caso,
mesma ordem de
criação que está nas tabelas Autor e Editora.
especificada no
esquema da tabela
Para finalizar os exemplos, vamos fazer a criação de uma nova tabela no nosso
Livro, do modelo modelo, chamada AUTOR_JOVEM com os mesmos campos da tabela AUTOR. Depois,
relacional exemplo. vamos inserir nesta nova tabela os autores da tabela AUTOR com nascimento posterior a
01/01/1980. Como ficariam os comandos SQL para realizar essas ações? Comecemos pela
Comentário criação da nova tabela.
CREATE TABLE AUTOR_JOVEM(
37
112 é o código do
autor anteriormente CodAutor INTEGER NOT NULL,
cadastrado. Nome CHAR(50) NOT NULL,
Nascimento DATE NOT NULL,
Comentário
PRIMARY KEY (CodAutor),
38
O Valor 1 é o UNIQUE (Nome, Nascimento) );
código da editora
Agora vamos preencher essa tabela com os autores com nascimento posterior a
anteriormente
cadastrada. 01/01/1980.
INSERT INTO AUTOR_JOVEM
40](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-40-320.jpg)
![Banco de Dados
SELECT * FROM AUTOR WHERE Nascimento40 > ‘01/01/1980’;
Comentário
Atualizando Dados em Tabelas
39
Como o atributo
Para modificar o valor de atributos de uma ou mais tuplas (linhas), dependendo VALOR pode receber
dos critérios de seleção de quem será modificado, o comando UPDATE deve ser utilizado. A valores nulos (ele não
é NOT NULL) pela
sintaxe desse comando é: definição feita na
tabela, no capítulo
UPDATE nome_tabela SET lista_atributos com atribuições de valores
anterior, podemos
[WHERE condição de seleção das tuplas a serem modificadas] preenchê-lo com o
valor NULL.
Onde: nome_tabela - é a indicação da tabela em que se deseja efetuar a atualização
dos registros;
Comentário
lista_atributos com atribuições de valores – É a indicação de quais atributos
deverão ser atualizados e por qual valor. Esse trecho deve ter o seguinte formato: nome_ 40
Aqui fazemos a
atributo1 [, nome_atributo2, ....] = {valor ou expressão } seleção dos autores
com nascimento maior
A cláusula WHERE especifica quais dados da coluna serão alterados. Quando que 01/01/1980.
a cláusula WHERE (que é opcional) é omitida, o UPDATE deve ser aplicado a todas as Veremos o comando
tuplas da relação. Ou seja, todas as tuplas da relação serão modificadas. Por exemplo: se SELECT , o mais
importante da DML,
desejássemos reajustar o valor de todos os livros em 10%, usaríamos o seguinte comando: em detalhes, mais a
frente.
UPDATE LIVRO SET Valor = Valor * 1.141
Como no comando acima não foi especificada uma cláusula WHERE, todos os livros Comentário
cadastrados na tabela LIVRO seriam atualizados. Agora, vamos supor que desejássemos
alterar o endereço e a cidade da editora com CodEditora = 10. 41
O valor antigo
UPDATE EDITORA SET endereco = ‘Av. N.S. de Fátima, 456’, cidade = ‘João Pessoa42’ de cada livro vai
receber o valor antigo
WHERE CodEditora = 1; aumentado de 10%
Aqui não seriam atualizadas todas as editoras da tabela EDITORA, mas apenas a (representado na
fórmula pelo 1.1)
editora de código 10.
A cláusula WHERE aceita como condição um comando SELECT. Daremos mais detalhes do que pode Comentário
vir em uma cláusula WHERE mais à frente. Aguarde...
42
Veja que apenas
os campos endereço
Exluindo Dados de Tabelas e cidade, como
solicitado, seriam
atualizados. Os
Para excluir linhas (que satisfaçam uma determinada condição) de uma ou mais novos valores para os
tabelas, usa-se o comando DELETE FROM, cuja sintaxe é: atributos vëm entre
apóstrofos porque são
DELETE FROM Nome_Tabela do tipo caracter.
[WHERE Condição43]
Se omitirmos a cláusula WHERE, então o DELETE será aplicado a todas as tuplas Comentário
da relação, ou seja, TODOS os registros da tabela serão deletados (cuidado com esse
comando!). Porém, a tabela permanece no BD como uma tabela vazia. Por exemplo, o 43
A cláusula WHERE
especifica quais
comando: DELETE FROM LIVRO; Deletaria todos os registros da tabela livro, deixando a
linhas da tabela serão
mesma vazia. Vale ressaltar que a tabela (seu esquema) permanece. Logo, esse comando excluídas.
não é equivalente ao DROP TABLE (que apagaria o esquema da tabela do banco de dados e,
por consequência, todos os dados da tabela seriam deletados juntamente).
Quando a cláusula WHERE é especificada, apenas os registros que obedecem a
condição estabelecida são deletados. Por exemplo, excluir os registros da tabela autor cujo
41](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-41-320.jpg)
![Banco de Dados
codAutor seja igual a 15.
DELETE FROM AUTOR WHERE CodAutor = 15;
Comentário Consultando Dados em Tabelas
44
Você pode Chegamos, agora, no comando mais importante da SQL por ser o utilizado com mais
especificar os atributos
frequência: o SELECT. Este comando se tornou o mais importante da linguagem SQL devido
desejados
ao seu poder de consulta. Pois com ele poderemos realizar, entre outras coisas, consultas
em uma ou mais tabelas, realizar consultas aninhadas, fazer a aplicação de funções pré-
existentes e utilizar operações relacionais (união, diferença, interseção e obviamente
seleção) com extrema simplicidade na manipulação das tabelas. A estrutura básica do
comando SELECT é:
Comentário
SELECT → PROJEÇÃO da álgebra relacional
45
Ou pode utulizar
o * (asterisco) que FROM → Onde a pesquisa será feita (uma ou mais tabelas)
indica que se quer
projetar TODAS as
colunas da(s) tabela(s) WHERE → Condições da SELEÇÃO
espedificada(s) na
cláusula FROM. Em resumo, a cláusula SELECT corresponde à operação de projeção da álgebra
relacional. Usada para listar os atributos desejados do resultado de uma consulta. A
cláusula FROM corresponde A especificação de onde a pesquisa será realizada. Em uma ou
mais tabelas (quando for usada mais de uma tabela, será aplicada a operação de produto
Comentário cartesiano da álgebra relacional). A cláusula WHERE corresponde à operação de seleção
da álgebra relacional, onde são especificadas as condições de pesquisa na(s) tabela(s)
46
Veja que, na cláusula identificadas na cláusula FROM.
WHERE espedificamos
a condição de pesquisa
que, no caso, é o
código ser igual a 5.
Vamos dar um exemplo. Selecione todas as informações da tabela AUTOR. Haveria
duas formas de realizar essa consulta:
SELECT CodAutor, Nome, Nascimento44 FROM AUTOR ; ou
SELECT45 * FROM AUTOR ;
Outro exemplo seria: Selecione todas as informações sobre o autor de código 5.
SELECT * FROM AUTOR WHERE CodAutor = 546;
Além dessa parte básica o comando SELECT tem várias outras que iremos explicando
nas próximas seções, começando da utilização mais simples, até chegar na mais elaborada.
Para dar uma ideia, a sintaxe completa do comando é:
SELECT [DISTINCT] nome_coluna,....
FROM nome_tabela, ....
[WHERE (condições)]
[GROUP BY nome_coluna, ....] [HAVING (condições)]
42](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-42-320.jpg)
![Banco de Dados
[{INTERSECT | MINUS | UNION} outro_comando_select]
[ORDER BY nome_coluna {ASC | DESC}, ....];
Cada cláusula permite a especificação de algum elemento referente às operações
relacionadas a álgebra relacional :
SELECT - o que deseja-se na tabela de resultado
FROM - de onde retirar os dados necessários
WHERE - condições para busca dos resultados
GROUP BY - agrupamento de resultados
HAVING - condições para a definição de grupos na tabela de resultados
INTERSECT - permite a interseção de tabelas
MINUS - permite a diferença entre tabelas
UNION - permite a união de tabelas
ORDER BY - estabelece a ordenação lógica da tabela de resultados (ASC – ordenação
ascendente, DESC – ordenação descendente)
É importante ressaltar que o resultado de qualquer comando SELECT é uma tabela
com as tuplas (e os atributos destas) que atendam aos critérios especificados. Para mostrar
esse ponto, além de tomarmos como base o mesmo modelo exemplo que vem sendo
utilizado para demonstrar as consultas das seções a seguir, vamos fazer uso das Relações
mostradas nas Tabelas 27, 28 e 29 que representam exemplos do modelo base preenchido.
Tabela 27 - Relação Editora
Cod_Editora (PK) Razao Endereco Cidade
1 Sextante Av. Hortências, 234 Porto Alegre
2 Fantasy R. 24 horas, 55 São Paulo
3 Bookman Av. das Ubaias, 303 Recife
Tabela 28 - Relação Autor
Cod_Autor (PK) Nome Nascimento
110 Pedro Alves 18/03/1955
111 Carolina Dantas 22/02/1970
112 Olívia Duncan 10/01/1968
43](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-43-320.jpg)




![Banco de Dados
As funções de agregação não podem ser combinadas a outros atributos da tabela
no resultado da consulta. Assim, a consulta a seguir não seria possível:
Restringindo a Consulta de Dados em Tabelas
Para restringir as consultas realizadas com o SELECT, precisamos fazer uso da
cláusula WHERE. Essa cláusula especifica quais linhas da(s) tabela(s) listada(s) na cláusula
FROM serão afetadas pela condição. Se nenhuma cláusula WHERE for especificada, a
consulta retornará todas as linhas da tabela, como visto nas seções anteriores. Na cláusula
WHERE é especificada a condição de restrição fazendo uso de operadores lógicos (AND, OR
e NOT) e relacionais (=, <>, >, <, >= e <=). A condição de WHERE pode ser de três tipos:
comparação, ligação entre tabelas (Join) e subconsultas (Sub-Queries). Vamos estudar cada
uma delas.
Comparação
Em geral, a comparação é realizada fazendo uso de uma condição composta por:
Expressão Operador Relacional Expressão
Onde, a condição é verdadeira quando a 1a expressão atende ao operador
relacional sobre a 2ª. Por exemplo, selecionar os livros publicados após 2008 (vide resultado
da consulta na Tabela 38):
SELECT * FROM LIVRO WHERE Ano_Publicacao > ‘2008’;
Tabela 38 - Relação Resultante
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
Banco de Dados 110 3 150,00 2009
O Estranho 111 1 45,00 2010
O Conhecido 111 1 55,00 2009
BD Distribuídos 110 3 98,00 2010
Também, podem ser utilizadas na comparação algumas cláusulas para trazer
facilidades para a seleção de dados. Vamos a elas!
» WHERE atributo [NOT] BETWEEN valor1 AND valor2;
Busca por intervalos de valores compreendidos entre os valores 1 e 2 (inclusive).
A variação é usar na frente do BETWEEN a cláusula NOT, neste caso, a busca é por
valores que estejam FORA do intervalo. Por exemplo, selecionar os livros com valor
de 50,00 a 100,00 (Resultado na Tabela 39).
48](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-48-320.jpg)
![Banco de Dados
SELECT * FROM LIVRO
Tabela 39 - Relação Resultante
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
O Conhecido 111 1 55,00 2009
BD Distribuídos 110 3 98,00 2010
Se se desejasse os livros fora do intervalo (ou seja, mais baratos que 50 e mais caros
que 100) seria usada a cláusula NOT (Resultado na Tabela 40).
SELECT * FROM LIVRO
WHERE Valor NOT BETWEEN 50.00 AND 100.00;
Tabela 40 - Relação Resultante
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
Banco de Dados 110 3 150,00 2009
O Estranho 111 1 45,00 2010
Sucesso 112 2 35,00 2000
Arquitetura de BD 110 3 110,00 2007
Comentário
56
O caracter
especial usado para
WHERE atributo [N OT] LIKE ‘padrão’ representação de
padrões muda de
Esta cláusula busca por padrões em atributos do tipo CHAR. A condição é satisfeita
SGBD para SGBD.
quando o valor do atributo é igual ao valor do padrão. Caracteres especiais56 são
utilizados para construção do padrão, tais como:
“%” ou “*” → Usados para representar zero ou mais caracteres. Comentário
“_” ou “?” → Usados para representar um único caractere.
57
Observe que o
[a-f] : busca por qualquer caractere entre ´a´ e ´f´ (usado no SQL-Server). padrão vem entre
apóstrofos. Observe
Vamos dar alguns exemplos. Selecionar todos os livros cujo título tenha 7 caracteres também que é usada
e inicie com a letra S (resultado na Tabela 41). uma interrogação (?)
para cada caractere do
SELECT * FROM Livro WHERE TitLivro LIKE ‘S??????’57; nome. Como se deseja
que a letra S seja a
Tabela 41 - Relação Resultante primeira. Ela vem
escrita no padrão.
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
Sucesso 112 2 35,00 2000
Comentário
Selecionar todos os livros que tenham a palavra BD no seu título (resultado na 58
Aqui o símbolo
Tabela 42). % representa que
pode existir qualquer
SELECT * FROM Livro WHERE TitLivro LIKE ‘%BD%58’; número de caracteres
antes ou depois da
palavra BD.
49](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-49-320.jpg)
![Banco de Dados
Tabela 42 - Relação Resultante
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
Arquitetura de BD 110 3 110,00 2007
BD Distribuídos 110 3 98,00 2010
Da mesma forma que se usa o LIKE, também pode ser usado o NOT LIKE. Neste
último caso, é devolvida na consulta os valores que NÃO obedecem ao padrão
especificado. Uma observação importante é que LIKE e NOT LIKE só se aplicam
sobre atributos do tipo CHAR.
» WHERE atributo IS [NOT] NULL
Essa cláusula testa a existência de valores nulos (NULL) ou não nulos (NOT NULL).
Ele faz com que a consulta retorne as tuplas da relação cujo atributo em questão
seja nulo ou não nulo, conforme a cláusula sendo utilizada. Para dar exemplo de
uso dessa cláusula, vamos supor que a relação LIVRO seja a da tabela 43. Assim,
vamos a realizar a seguinte consulta: selecionar todos os livros que estão sem preço
definido (resultado na Tabela 44).
Comentário SELECT * FROM Livro WHERE Valor IS NULL59
Tabela 43 - Relação Livro
59
Vai checar entre
todos os livros aqueles
que tem no valor do TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
livro NULL.
Banco de Dados 110 3 150,00 2009
O Estranho 111 1 45,00 2010
Sucesso 112 2 NULL 2000
Arquitetura de BD 110 3 110,00 2007
O Conhecido 111 1 55,00 2009
BD Distribuídos 110 3 NULL 2010
Tabela 44 - Relação Resultante
TitLivro (PK) CodAutor (FK) CodEditora (FK) Valor Ano_Publicacao
Sucesso 112 2 NULL 2000
BD Distribuídos 110 3 NULL 2010
» WHERE expressão [NOT] IN (Valores)
Teste de pertinência elemento-conjunto. O teste da condição é verdadeiro se o
valor da expressão for igual (ou diferente, se for usado o NOT) a um dos valores
especificados entre parênteses. Por exemplo, selecionar as editoras com sede em
São Paulo ou Rio de Janeiro (resultado na Tabela 45).
50](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-50-320.jpg)


![Banco de Dados
Subconsultas (Sub-Queries)
Na condição especificada na cláusula WHERE podem ser usadas subconsultas. Essas
subconsultas podem retornar um valor simples, ou um conjunto de valores. Vamos olhar
cada caso.
Subconsultas que retornam um valor simples
Neste caso, a subconsulta deve retornar uma única tupla. Para isso, podem-se usar
as funções de agregação (AVG,MIN,MAX,...). Esse tipo de subconsulta é utilizado para fazer
a comparação elemento-elemento e tem o seguinte formato:
WHERE expressão {= | <> | > | >= | < | <=} (Subconsulta)
Onde: subconsulta é outra consulta (SELECT) que pode conter qualquer uma das
cláusulas anteriormente estudadas. Por exemplo, selecionar os títulos dos livros mais caros
que a média de preço dos livros. Veja que primeiro precisamos calcular a média de preço
dos livros para depois buscar por aqueles livros que tem seu preço acima da média. Logo, a
maneira de fazer isso é usando uma subconsulta, como veremos a seguir:
SELECT TitLivro FROM Livro
WHERE Valor > (SELECT AVG (Valor) FROM Livro) ;
Na execução da subconsulta, seria calculado o valor da média dos livros (a partir da
Tabela 43), que seria o valor 60. Depois, a mesma tabela seria avaliada pela consulta externa,
para obter os títulos de livros cujos valores fossem maiores do que a média calculada na
subconsulta, resultando na Tabela 49.
Tabela 49 - Relação Resultante
TitLivro
Banco de Dados
Arquitetura de BD
Subconsultas que retornam um conjunto de valores
Usadas para fazer comparação elemento-conjunto. Em outras palavras, elas
estabelecem uma relação de pertinência (�) entre elementos e conjuntos (tabelas). Sua
avaliação retorna um valor booleano. Esse tipo de subconsultas pode ser definido através
das cláusulas IN, ANY, ALL e EXISTS. Vamos dar uma olhada em cada uma dessas cláusulas.
» WHERE expressão [NOT] IN (Sub-Consulta) – já estudamos o IN anteriormente
neste capítulo em consultas simples. Agora, estamos vendo o uso do mesmo com
subconsultas. Essa cláusula verificaria se o resultado da expressão está contido no
subconjunto de valores retornado pela subconsulta. Por exemplo, selecionar o
nome e a data de nascimento dos autores de livros que não tem valor definido (ou
seja, que tem valor NULL).
SELECT Nome, Nascimento FROM Autor
WHERE CodAutor IN
(SELECT CodAutor FROM Livro
53](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-53-320.jpg)

![Banco de Dados
Quando na comparação é utilizado <> ALL, a cláusula passa a ter o mesmo efeito
que a cláusula NOT IN.
» WHERE expressão [NOT] EXISTS (Sub-consulta) - verifica a existência de dados
numa lista de valores da subconsulta. Retorna VERDADEIRO ou FALSO, conforme
a subconsulta retorne ou não linhas de resultado. Por exemplo, selecione o nome
de todos os autores que têm livros publicados nas editoras Fantasy ou Bookman
(resultado na Tabela 54).
SELECT Au.Nome FROM AUTOR Au
WHERE EXISTS (SELECT * FROM LIVRO Li, EDITORA Ed
WHERE Li.CodAutor=Au.Cod_Autor AND
Li.CodEditora=Ed.Cod_Editora AND
Ed.Razao IN (‘Fantasy, ‘Bookman’));
Tabela 54 - Relação Resultante
Nome
Pedro Alves
Olívia Duncan
Ordenando Resultados
Para ordenar os resultados das consultas pelos valores de uma ou mais colunas
(atributos), utiliza-se a cláusula ORDER BY. As linhas são ordenadas pela primeira coluna
(atributo) especificada após o ORDER BY. Quando as linhas de uma coluna possuem valores
iguais, estas serão classificadas pelo valor da segunda coluna especificada após o ORDER BY
e assim por diante. Há dois tipos de ordenação:
» ASC → Ascendente (default)
» DESC → Decrescente
Vamos ao exemplo: Selecionar o nome e o nascimento dos autores em ordem
decrescente do nascimento. Para datas iguais, considerar a ordem alfabética do nome do
autor (resultado na Tabela 54).
SELECT Nome, Nascimento FROM Autor
ORDER BY Nascimento DESC, Nome ASC;
Tabela 54 - Relação Resultante
Nome Nascimento
Carolina Dantas 22/02/1970
Olívia Duncan 10/01/1968
Pedro Alves 18/03/1955
55](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-55-320.jpg)




![Banco de Dados
Interseção (INTERSECT)
Retorna apenas as linhas que pertencem às duas relações resultantes, se elas forem
compatíveis, sem repetição. Por exemplo, selecionar o nome de todas as pessoas que são
médicos e pacientes ao mesmo tempo.
(SELECT Nome FROM Medico)
INTERSECT
(SELECT Nome FROM Paciente);
Selecionar todos os clientes da agência A1 com empréstimo e depósito.
(SELECT * FROM Depositante WHERE Agencia = ‘A1’)
INTERSECT
(SELECT * FROM Devedor WHERE Agencia = ‘A1’);
Exceção (EXCEPT ou MINUS)
Retorna apenas as linhas que pertencem à primeira tabela, com exceção das que
aparecem na segunda. Em outras palavras, retorna somente as linhas da primeira query
(consulta) que não estão presentes no resultado da segunda query. Por exemplo, selecionar
o nome de todas as pessoas que são médicos e não são pacientes.
(SELECT Nome FROM Medico)
EXCEPT
(SELECT Nome FROM Paciente);
Selecionar todos os clientes da agência A1 que possuem conta, mas não fizeram
empréstimo.
(SELECT * FROM Depositante WHERE Agencia = ‘A1’)
EXCEPT
(SELECT * FROM Devedor WHERE Agencia = ‘A1’);
Manipulando Visões
Visões são tabelas virtuais que não ocupam espaço físico e são criadas a partir de
tabelas reais. Elas permitem criar tabelas personalizadas, de acordo com o perfil do usuário.
Visões são ótimas para substituir consultas frequentemente usadas. Para criar uma visão
utilizamos o seguinte comando:
CREATE VIEW Nome_Visão [Colunas_visão] AS
(ExpressãoConsultaPreenchimentoVisao)
Por exemplo, criar uma visão com os clientes que tem conta ou empréstimo no
banco.
CREATE VIEW TodosClientes AS
(SELECT * FROM Depositante)
UNION
(SELECT * FROM Devedor);
Outro exemplo, criar uma visão com os livros da editora Bookman com 10% de
desconto.
60](https://image.slidesharecdn.com/bancodedados-volume4v10-110216153847-phpapp02/85/Banco-de-dados_-_volume_4_v10-60-320.jpg)