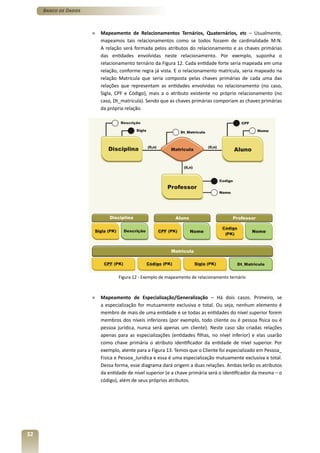
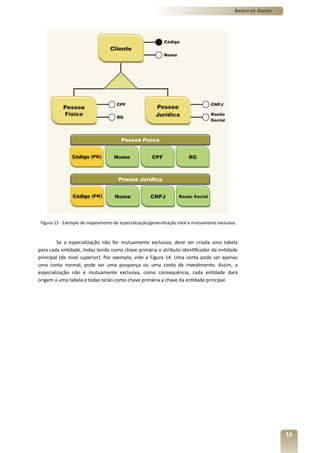
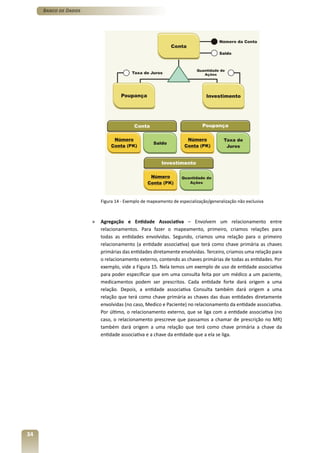
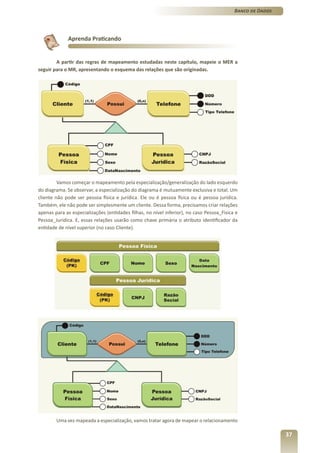
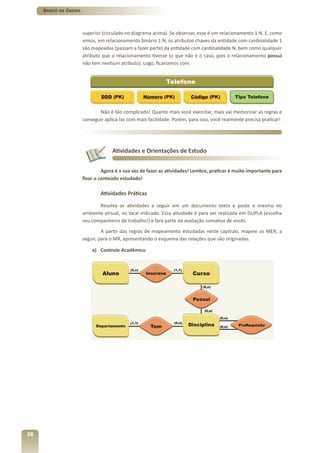
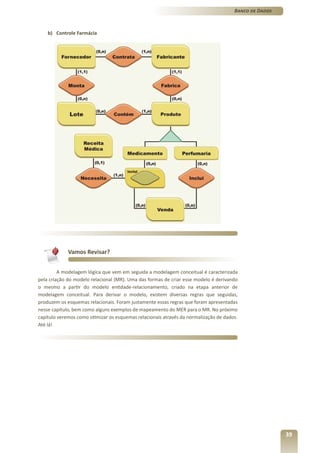
1) O documento apresenta o terceiro volume do curso de Banco de Dados, que aborda o modelo relacional e a normalização de dados.
2) O capítulo 7 introduz os conceitos fundamentais do modelo relacional, como tabelas, restrições de integridade e as 12 regras de Codd.
3) Os capítulos 8 e 9 discutem a derivação do modelo relacional a partir do modelo conceitual e a normalização de dados, respectivamente.








![Banco de Dados
poderiam ser armazenados dados como o CPF, o nome e o telefone de cada empregado. A
tabela como um todo representaria os empregados da empresa. Cada coluna representaria
um atributo (ex: a primeira coluna da Tabela 1 é o CPF ). E cada linha da tabela representa os
dados de um empregado. Por exemplo, a primeira linha da Tabela 1 se refere à empregada
de CPF número 987675456-98, de nome Ana Marques e cujo telefone é 3245-8976.
Tabela 1 - Tabela ou Relação Empregado
CPF Nome Telefone
987675456-98 Ana Marques 3245-8976
765456243-45 João Pontes 3124-5645
213415467-89 Marcos Alves 3456-8923
567324980-03 Tânia Gomes 3455-9098
Comentário
Matematicamente, define-se uma relação como um subconjunto de um produto
cartesiano de uma lista de domínios2. Assim, suponha que D1 denote o domínio do atributo
2
Um domínio contém
A1, D2 denote o domínio do atributo A2 e Dn denote o domínio do atributo N da tabela T1.
os valores possíveis
Qualquer linha da tabela que possui estes atributos é denotada pela tupla3 (d1,d2,...,dn) em para um determinado
que d1, d2 e dn têm como valores possíveis (domínios), respectivamente D1, D2 e Dn. Em atributo da relação.
geral, uma instância de T1 é um subconjunto de D1 X D2 X ... X Dn.
O conjunto de atributos de uma relação é chamado de esquema da relação. O
esquema de uma relação é denotado por : R[A1 D1, ..., An Dn] onde: Comentário
R é o nome da relação; 3
Uma tupla é uma
A1, ..., An é a lista de atributos da relação R e ocorrência particular
de um elemento da
D1, ..., Dn são os domínios de cada um dos atributos da relação R. tabela. Falaremos
sobre esse conceito,
Frequentemente, é utilizada uma notação simplificada em que é omitida a definição em detalheas, mais a
do domínio de cada atributo da relação: R[A1, ..., An]. Por exemplo, o esquema da relação frente.
representada na Tabela 1 seria: Empregado[CPF char4(11), Nome char(50), Telefone
char(9)] ou, na notação simplificada, teríamos Empregado[CPF, Nome, Telefone].
Na criação dos esquemas das relações o nome das relações ou tabelas devem ser Comentário
únicos no banco de dados, devem ser escritos no singular e, de preferência, devem ser
nomes curtos. Se for usado um nome composto, este deve ser separado por um underline 4
O tipo char equivale
(_), por exemplo Pessoa_Fisica ou Pessoa_Juridica. ao tipo string das
linguagens de
O atributo identificador da relação é apresentado sublinhado (esse atributo programação, onde
você pode digitar
identificador dará origem à chave primária da relação, como veremos mais a frente). Assim,
letras, números e
se CPF fosse o atributo identificador teríamos: Empregado[CPF, Nome, Telefone]. símbolos. Quando
você define um tipo
O grau de uma relação é o número de atributos que a compõe. Por exemplo, o grau char, você tem de
da relação Empregado[CPF, Nome, Telefone] é três, porque essa relação possui 3 atributos. especificar o tamanho
do que preencherá
Uma particularidade referente à definição de relação é que, nesta definição, não o mesmo. Esse tipo
existe qualquer tipo de ordenação ou de definição de ordenação. Assim, por exemplo, as pode variar de nome
duas relações representadas pelas Tabelas 1 e 2 são consideradas idênticas. Afinal, o que de SGBD para SGBD
mas sempre vai ter um
mudou de uma tabela para outra foi apenas a ordem em que os valores de preenchimento correspondente.
da tabela aparecem.
9](https://image.slidesharecdn.com/livrobancodedadosvolume03-110216152920-phpapp01/85/Livro-banco-de_dados_volume_03-9-320.jpg)

![Banco de Dados
atributo que caracteriza a relação é expresso em uma coluna. Toda coluna de uma tabela
deve possuir um nome pelo qual será referenciada sempre que necessário. Na verdade,
ao criarmos uma tabela definimos, para cada uma de suas colunas, o seu nome (nome do
atributo) e também o seu tipo (numérico, alfabético, data, etc). Por exemplo, CPF, Nome e
Telefone são atributos (colunas ou campos) da Tabela Empregado, expressos na Tabela 3.
Um nome de atributo deve ser único em uma tabela e deve expressar o tipo de
informação que ele representa. E o valor de um atributo não deve poder ser decomposto
em mais de uma coluna.
Domínio do Atributo
Domínio de um atributo é a faixa de valores que esse atributo pode conter. Em
outras palavras, é o conjunto de valores que um determinado atributo pode assumir. Por
exemplo, para o atributo CPF da Tabela 3, o domínio seria o conjunto dos números naturais.
Em outras tabelas quaisquer, por exemplo, o domíno do atributo “dia do mês”seria o
conjunto dos números entre 1 e 31. O atributo “sexo” teria como domínio os mnemônicos
M (para masculino) ou F (para feminino) e assim por diante.
Sempre que identificamos um atributo de uma tabela, temos também uma ideia de
qual o tipo de informação que ele poderá vir a conter.
Chaves
Comentário
Uma chave5 é um atributo (ou conjunto de atributos) que identifica univocamente
cada entrada de uma relação. Ou seja, por meio de chaves podemos diferenciar as diversas
5
O conceito
de chave está
tuplas pertencentes a uma relação. Como consequência dessa definição, temos que os diretamente ligado
atributos chaves não podem apresentar valores duplicados, nem podem ser nulos. ao de identificador
da entidade ou
relacionamento que foi
NULO - Não devemos confundir o conceito de nulo com espaços em branco ou o número zero, por
estudado no volume
exemplo, que são valores conhecidos. Nulo é a ausência de informação. anterior, quando
foram detalhados os
Uma coluna de preenchimento obrigatório numa tabela deve possuir todos os seus valores não- componentes do MER.
nulos. Se, por exemplo, uma linha da tabela Empregado contiver um nulo na coluna Telefone,
significa que o telefone do empregado correspondente àquela linha é desconhecido. Assim, ou o
telefone não foi informado por algum motivo ou o empregado não possui telefone, de qualquer
forma, a informação está ausente na tabela.
Comentário
Uma definição mais formal para chave seria: seja R um esquema de relação. Se
dissermos que um subconjunto K de atributos de R é uma superchave6 para R, estaremos
6
Superchave é o
conjunto de um ou
considerando restrições para as relações r(R), nas quais não existem duas tuplas distintas
mais atributos que nos
com mesmos valores em todos os atributos de K. Isto é, se as tuplas t1 e t2 fazem parte da permitem identificar
relação r e t1 <> t2, então t1[K] <> t2[K]. de maneira unívoca
uma tupla de uma
Quando há a possibilidade de mais de um atributo (isoladamente) poder ser chave relação.
em uma relação, dizemos que esses atributos são chaves candidatas. Por exemplo, na Tabela
4, CPF e Nome poderiam ser chaves candidatas, porque poderiam ser atributos usados para
localizar uma entrada na tabela.
11](https://image.slidesharecdn.com/livrobancodedadosvolume03-110216152920-phpapp01/85/Livro-banco-de_dados_volume_03-11-320.jpg)


























































































![[UFMS Digital] BANCO DE DADOS - Videoaula do Módulo 1.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ufmsdigitalbancodedados-videoauladomdulo1-240915141630-a7f1e50e-thumbnail.jpg?width=640&height=640&fit=bounds)


























