Transferir como PDF, PPTX














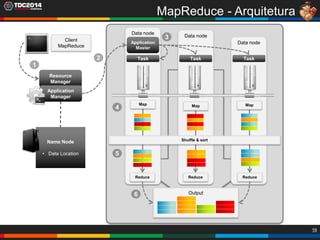
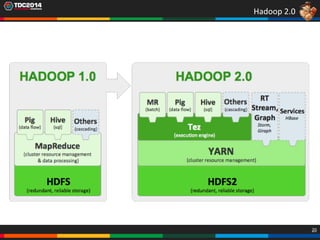
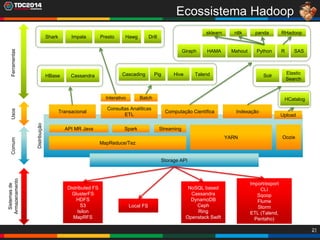


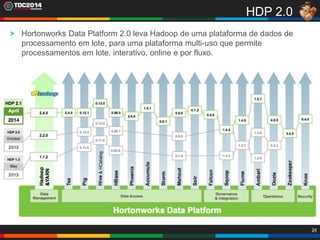
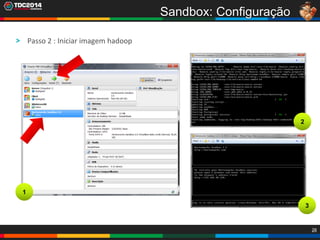
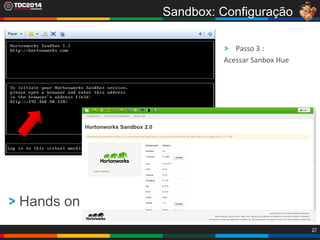
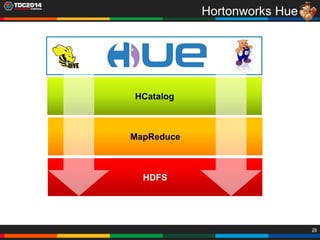
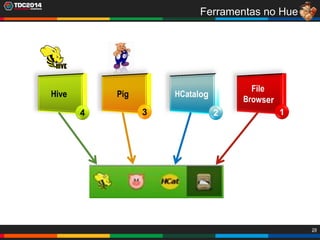
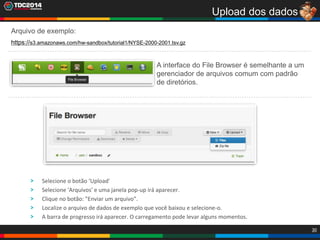
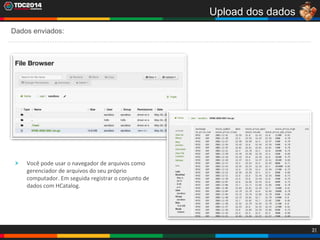
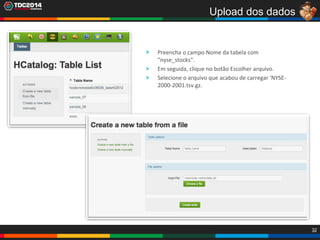
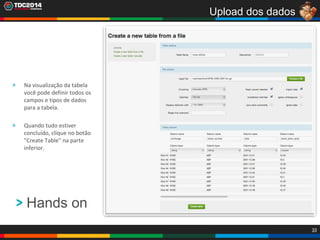

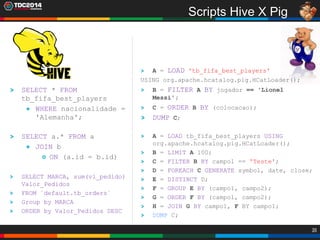

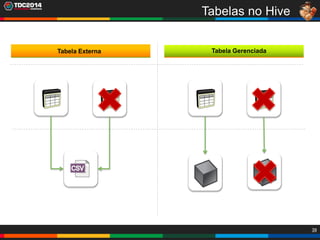
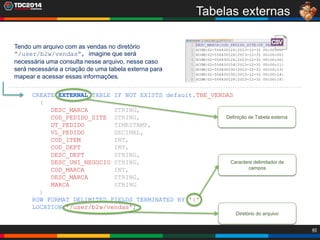

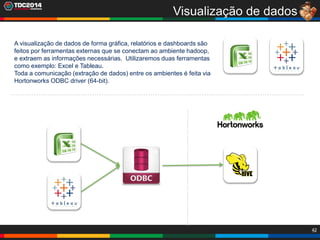
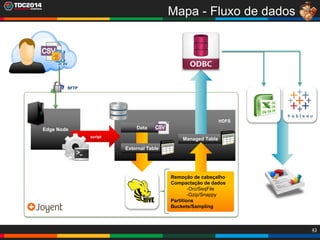
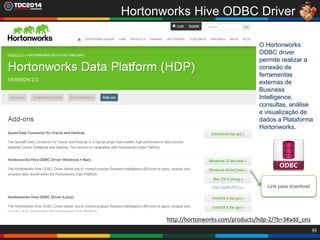
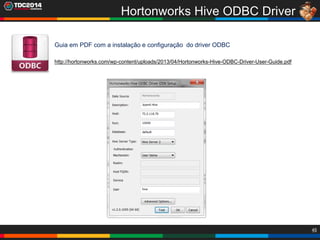
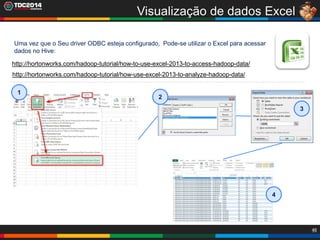
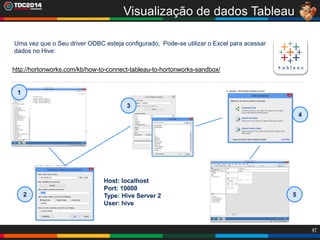



1. O documento apresenta uma história sobre Ryu, escolhido para analisar grandes volumes de dados do e-commerce Shadaloo usando Apache Hadoop. 2. Explica brevemente o que é Hadoop, sua arquitetura e ferramentas como HDFS, MapReduce, Hive e PIG. 3. Apresenta demonstrações práticas de como usar a sandbox Hortonworks para trabalhar com Hadoop, incluindo upload de dados, criação de tabelas Hive e execução de scripts.


























































