Transferir como PDF, PPTX





































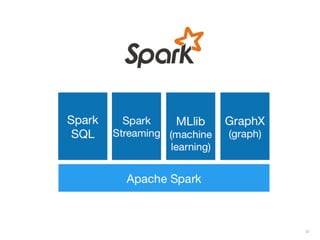
![EXEMPLO
define foo(array d)
if CPU = "a"
lower_limit := 1
upper_limit := round(d.length/2)
else if CPU = "b"
lower_limit := round(d.length/2) + 1
upper_limit := d.length
for i from lower_limit to upper_limit by 1
do_something_with(d[i])
end
62](https://image.slidesharecdn.com/workshopdatalakes-150826170028-lva1-app6891/85/Data-Lakes-com-Hadoop-e-Spark-Agile-Analytics-na-pratica-62-320.jpg)
![EXEMPLO
define foo(array d)
if CPU = "a"
lower_limit := 1
upper_limit := round(d.length/2)
else if CPU = "b"
lower_limit := round(d.length/2) + 1
upper_limit := d.length
for i from lower_limit to upper_limit by 1
do_something_with(d[i])
end
63
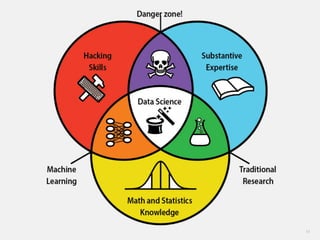
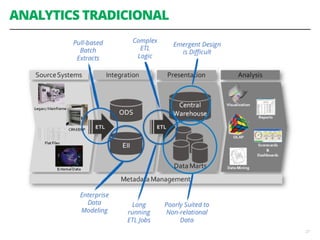
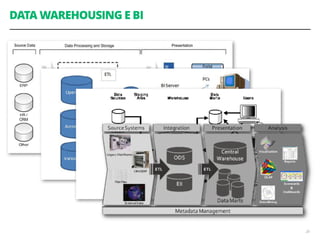
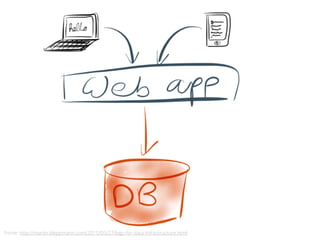
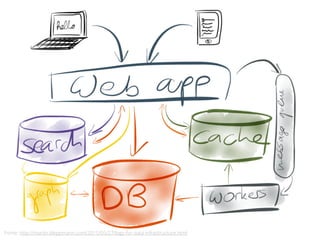
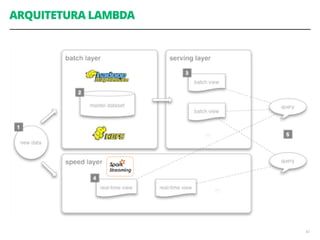
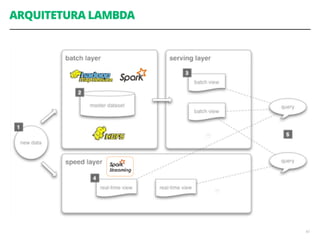
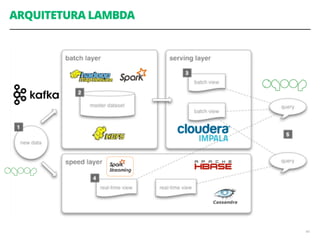
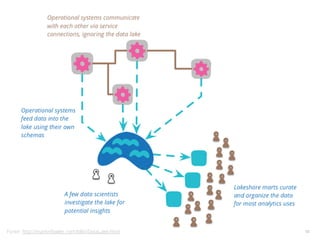
Acoplamento do código ao número de CPUs da máquina
Você precisa se preocupar em como dividir os
dados através dos diferentes nós de computação
Você precisa se preocupar explicitamente em como
acumular e consolidar a saída final a partir das
computações em paralelo](https://image.slidesharecdn.com/workshopdatalakes-150826170028-lva1-app6891/85/Data-Lakes-com-Hadoop-e-Spark-Agile-Analytics-na-pratica-63-320.jpg)















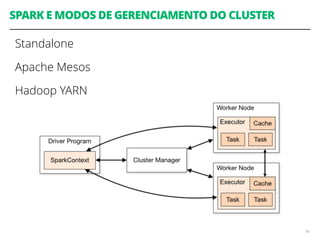







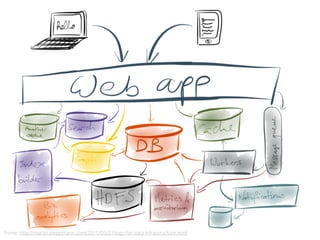
![RDD: EXEMPLOS DE TRANSFORMAÇÕES
map(f : T U) : RDD[T] RDD[U]
filter(f : T Bool) : RDD[T] RDD[T]
flatMap(f : T Seq[U]) : RDD[T] RDD[U]
union() : (RDD[T],RDD[T]) RDD[T]
join() : (RDD[(K, V)],RDD[(K, W)]) RDD[(K, (V, W))]
groupByKey() : RDD[(K, V)] RDD[(K, Seq[V])]
reduceByKey(f : (V,V) V) : RDD[(K, V)] RDD[(K, V)]
92](https://image.slidesharecdn.com/workshopdatalakes-150826170028-lva1-app6891/85/Data-Lakes-com-Hadoop-e-Spark-Agile-Analytics-na-pratica-92-320.jpg)
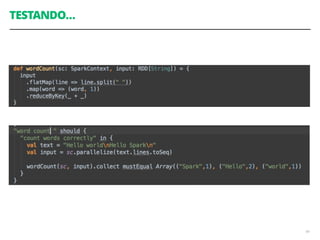
![count() : RDD[T] Long
collect() : RDD[T] Seq[T]
reduce(f : (T,T) T) : RDD[T] T
lookup(k : K) : RDD[(K, V)] Seq[V]
93
RDD: EXEMPLOS DE AÇÕES](https://image.slidesharecdn.com/workshopdatalakes-150826170028-lva1-app6891/85/Data-Lakes-com-Hadoop-e-Spark-Agile-Analytics-na-pratica-93-320.jpg)







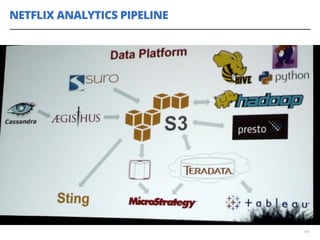
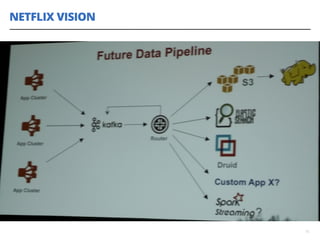
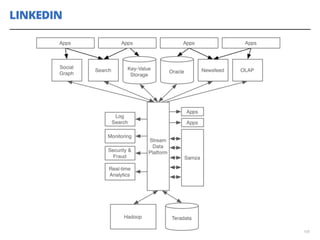
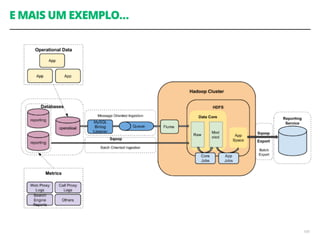




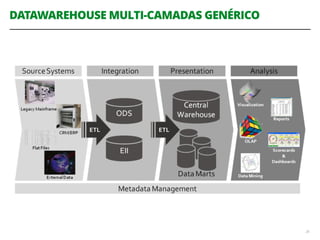
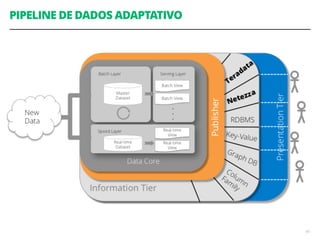
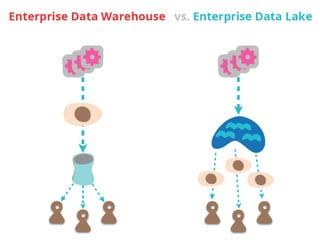
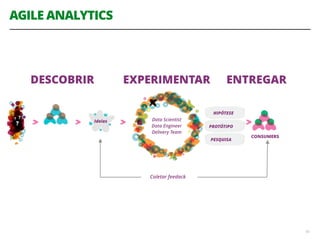
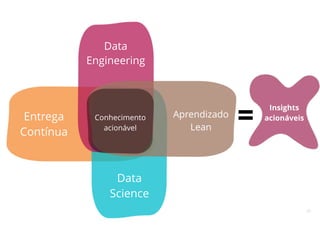
O documento discute a utilização de data lakes com Hadoop e Spark para análises ágeis, abordando as diferenças entre data warehousing tradicional e as novas arquiteturas de data lake. Também são apresentados conceitos sobre ingestão de dados, processamento em tempo real e a importância de permitir que desenvolvedores criem pipelines de dados de forma ágil. A conclusão enfatiza a necessidade de inovação e adaptação na análise de grandes volumes de dados.








































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)










