Transferir como PDF, PPTX

















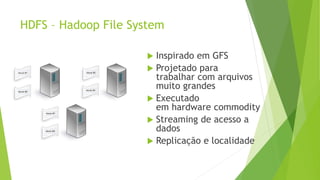
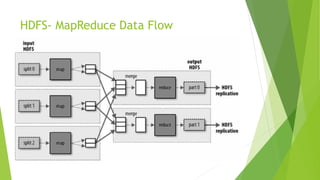


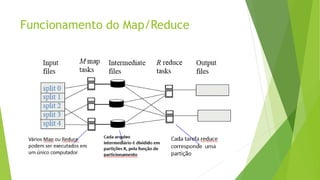
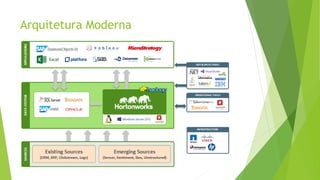
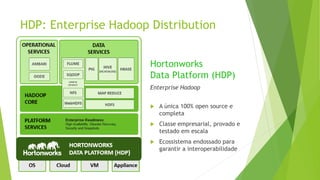













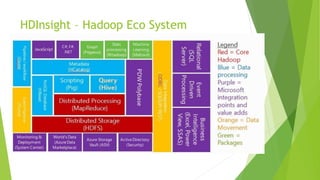


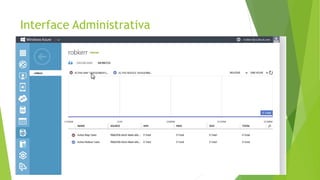




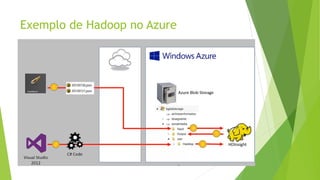
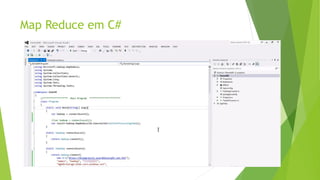
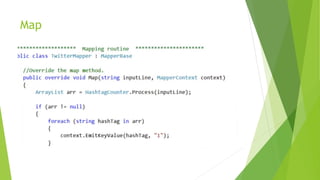
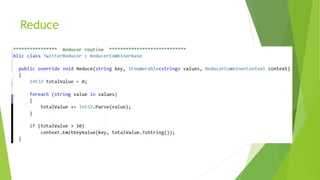


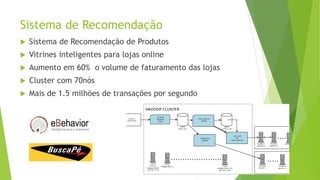

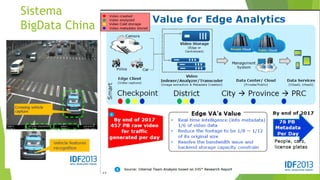
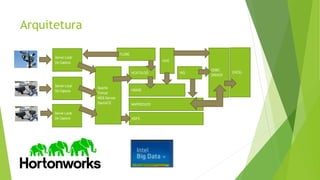

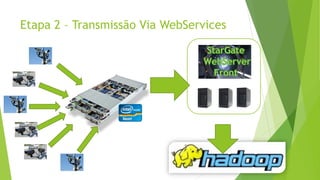

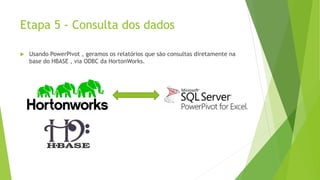
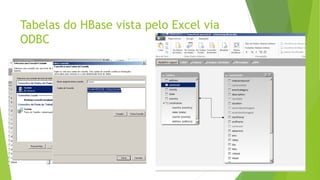
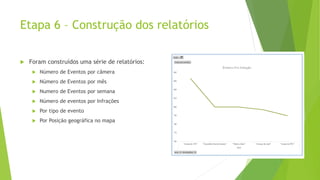
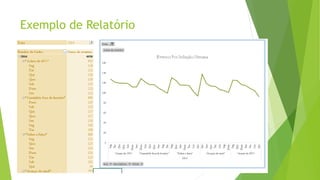
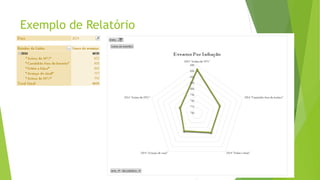
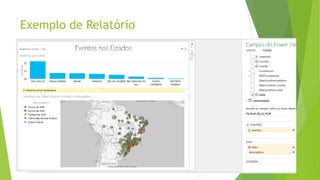

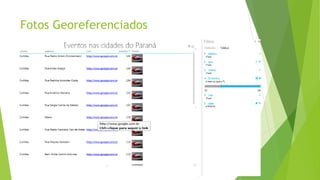


O documento discute a interoperabilidade do Big Data Hadoop com o Windows Azure, abordando conceitos de Big Data, ciência de dados e Hadoop, além de apresentar casos de uso práticos. É enfatizada a importância do Hadoop como uma solução escalável e confiável para o processamento de grandes volumes de dados e sua integração com ferramentas da Microsoft. O texto também destaca a formação de cientistas de dados e as oportunidades de análise no contexto de dados não estruturados.















































































