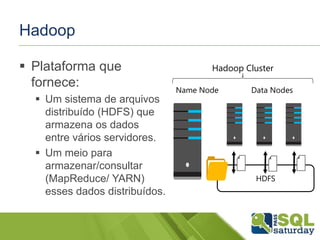
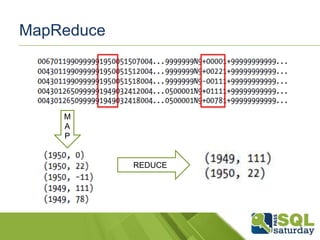
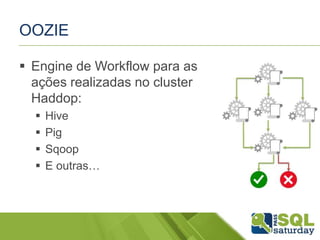
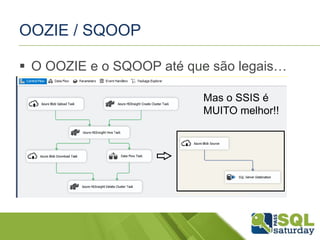
O documento apresenta uma introdução ao mundo do Big Data para DBAs, discutindo conceitos como Hadoop, HDInsight, MapReduce, Hive, Pig, Sqoop e Oozie. É demonstrado o uso dessas ferramentas em um cluster HDInsight no Azure para processar grandes volumes de dados de forma distribuída.