Baixado 172 vezes





![Alguns Projetos BigData
[2011] Psafe.com (Lockbox):
• 480 Servidores (64Gb RAM, 32Tb SATA)
• Distribuídos em 3 DCs
• 16 Racks por DC
• 10 Servidores por Rack
• Hadoop HDFS
[2013] SitePX (ElasticSearch):
• +5.000.000 Documentos
• Distribuídos em 10 instâncias AWS (Auto-Scalling)
• Resultados de busca em 0.4 Segundos
5](https://image.slidesharecdn.com/bsidessp-131124115604-phpapp01/85/BIGDATA-Da-teoria-a-Pratica-5-320.jpg)







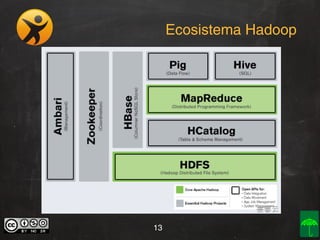
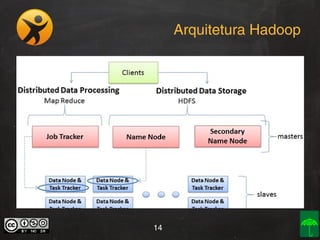
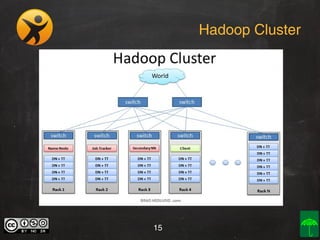
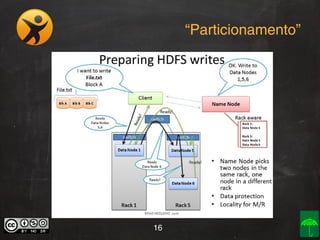






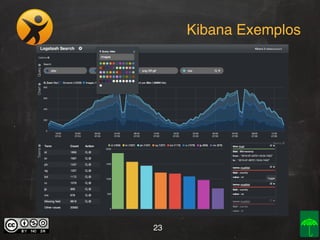
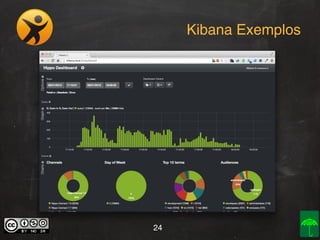
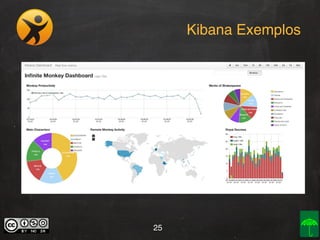
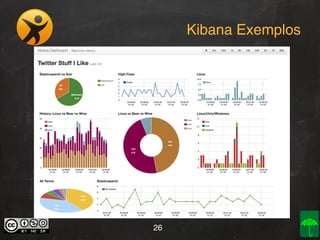
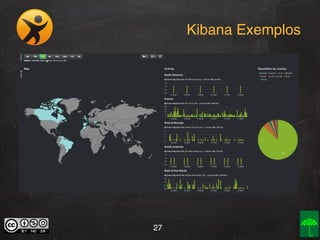
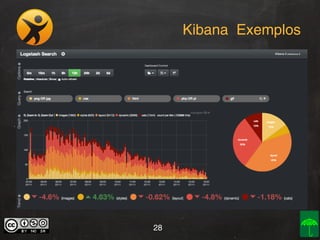


O documento aborda o conceito e aplicação de Big Data, destacando sua importância e os desafios enfrentados na implementação, como as premissas e categorizações noSQL. Também apresenta projetos práticos de Big Data e soluções como Hadoop, Elasticsearch, Logstash e Kibana para gerenciar grandes volumes de dados. O autor, Daniel Checchia, é um consultor com vasta experiência em tecnologia e e-commerce.













































































