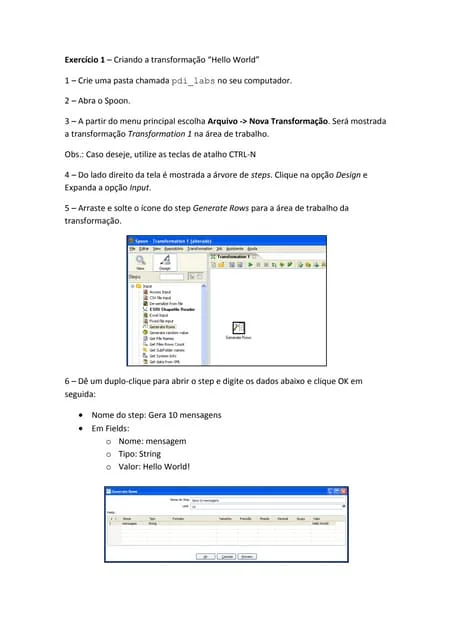
Transferir como PDF, PPTX








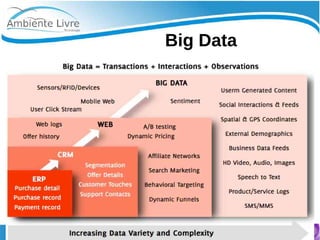
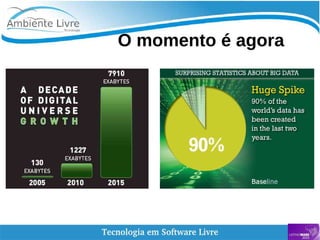











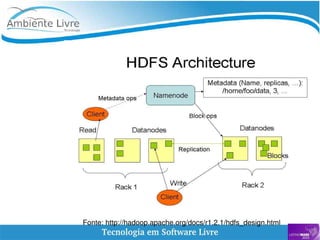
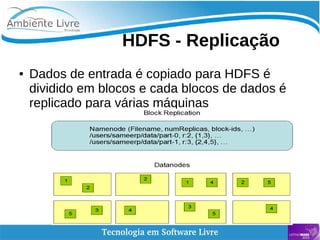


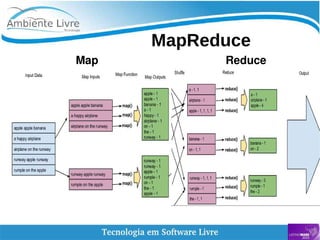

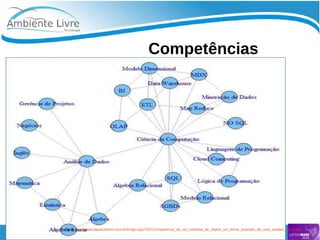

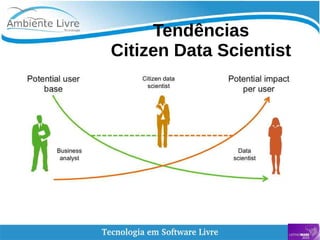







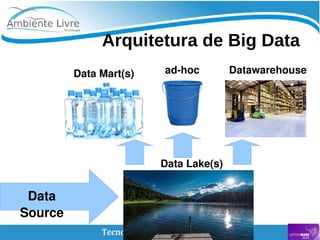


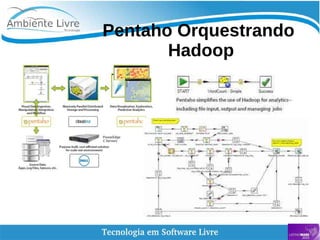
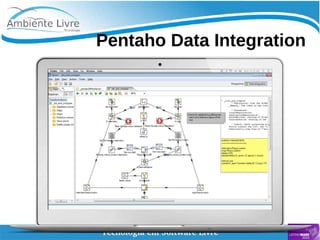

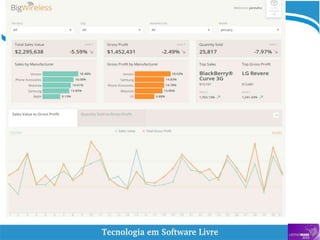
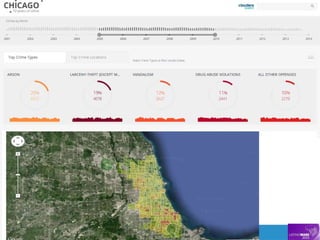





O documento aborda a relação entre big data, Hadoop e data lakes, destacando a experiência do palestrante Marcio Junior Vieira em software livre e sua atuação como instrutor. Ele apresenta a importância de ferramentas open source como Hadoop para o processamento de grandes volumes de dados, além de discutir a necessidade crescente de cientistas de dados no mercado. O texto também menciona desafios e recomendações para a adoção de big data nas empresas, enfatizando a transformação de processos e a cultura organizacional necessária.
























![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)