Baixado 31 vezes







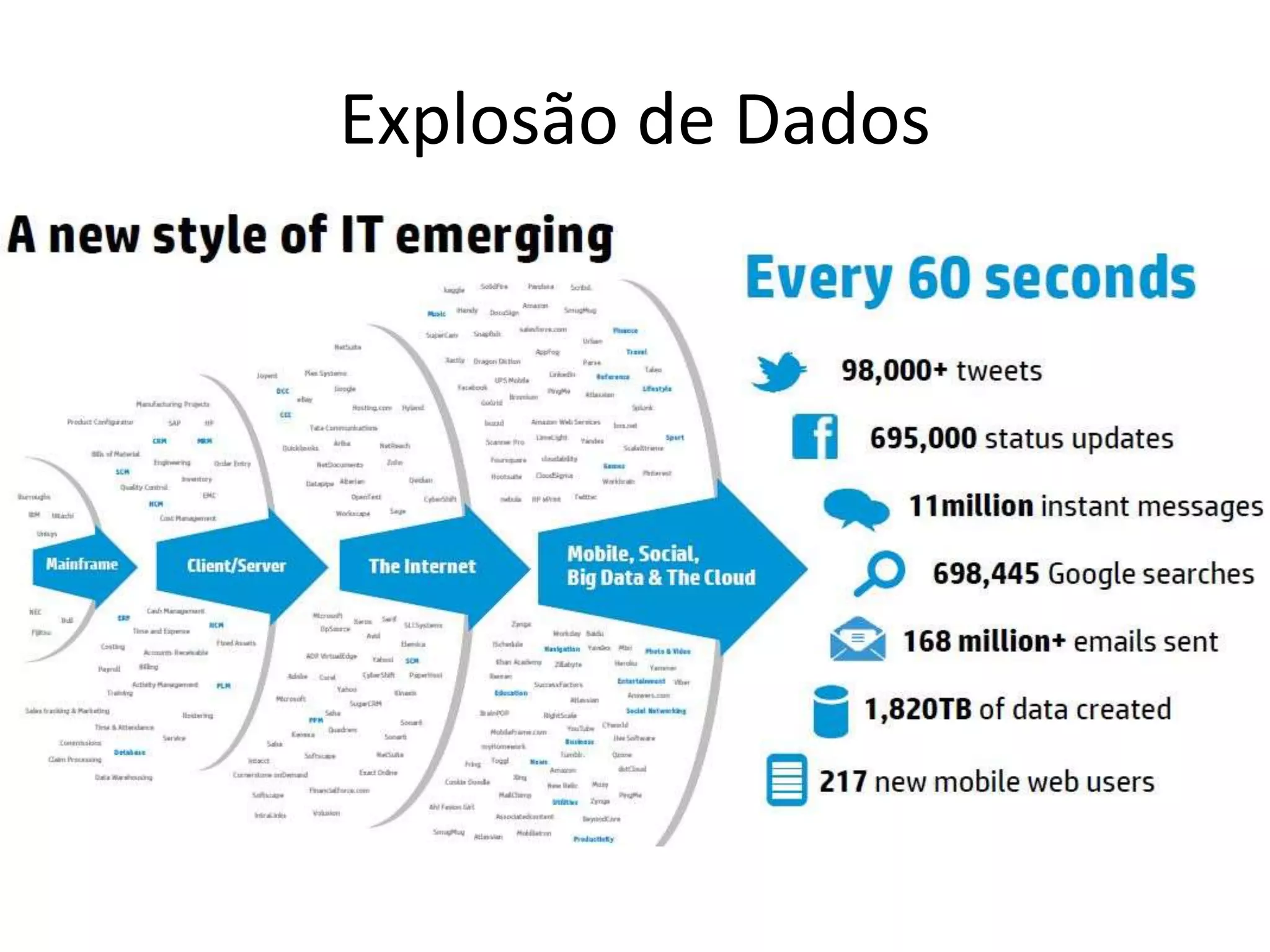










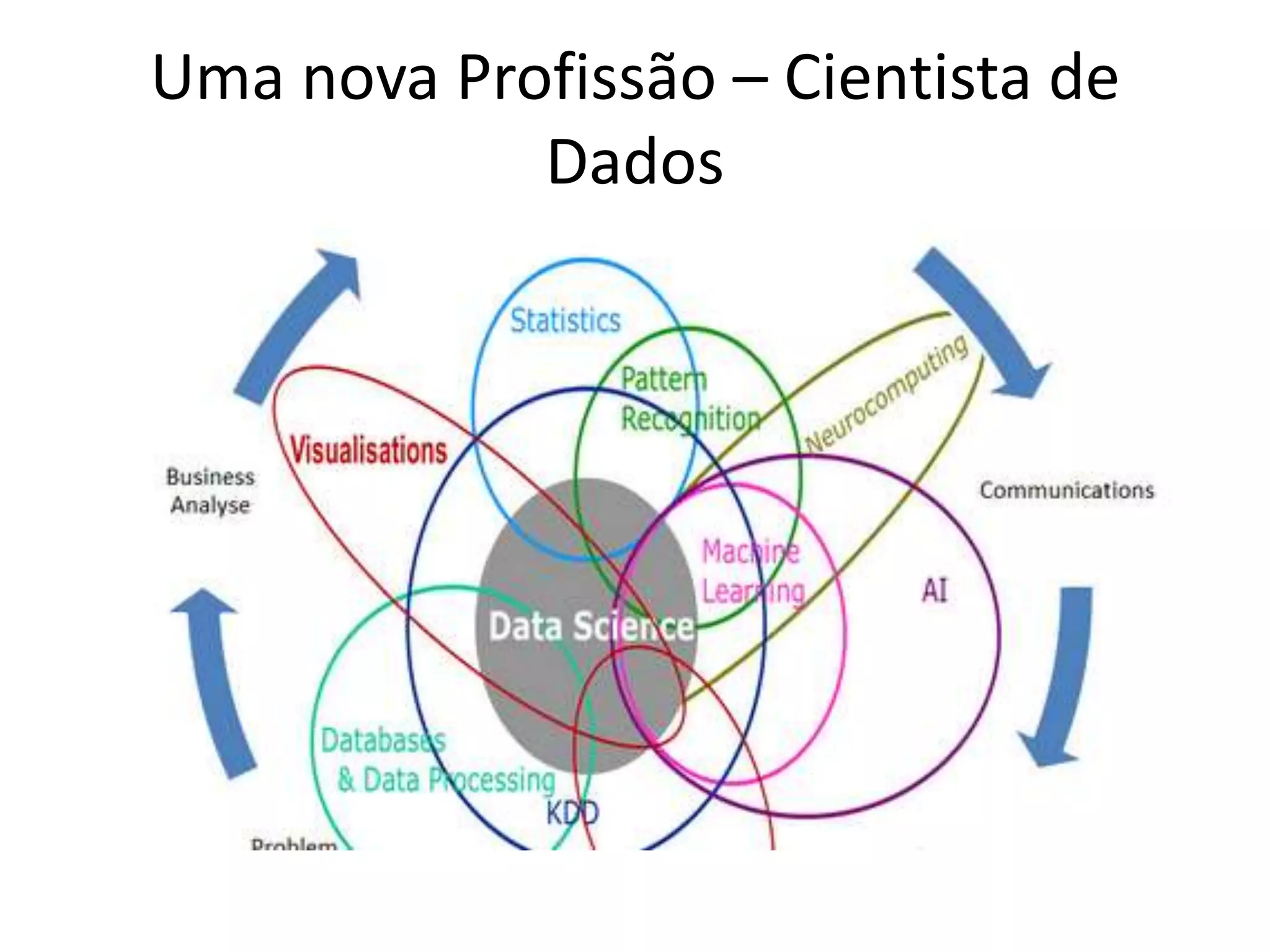




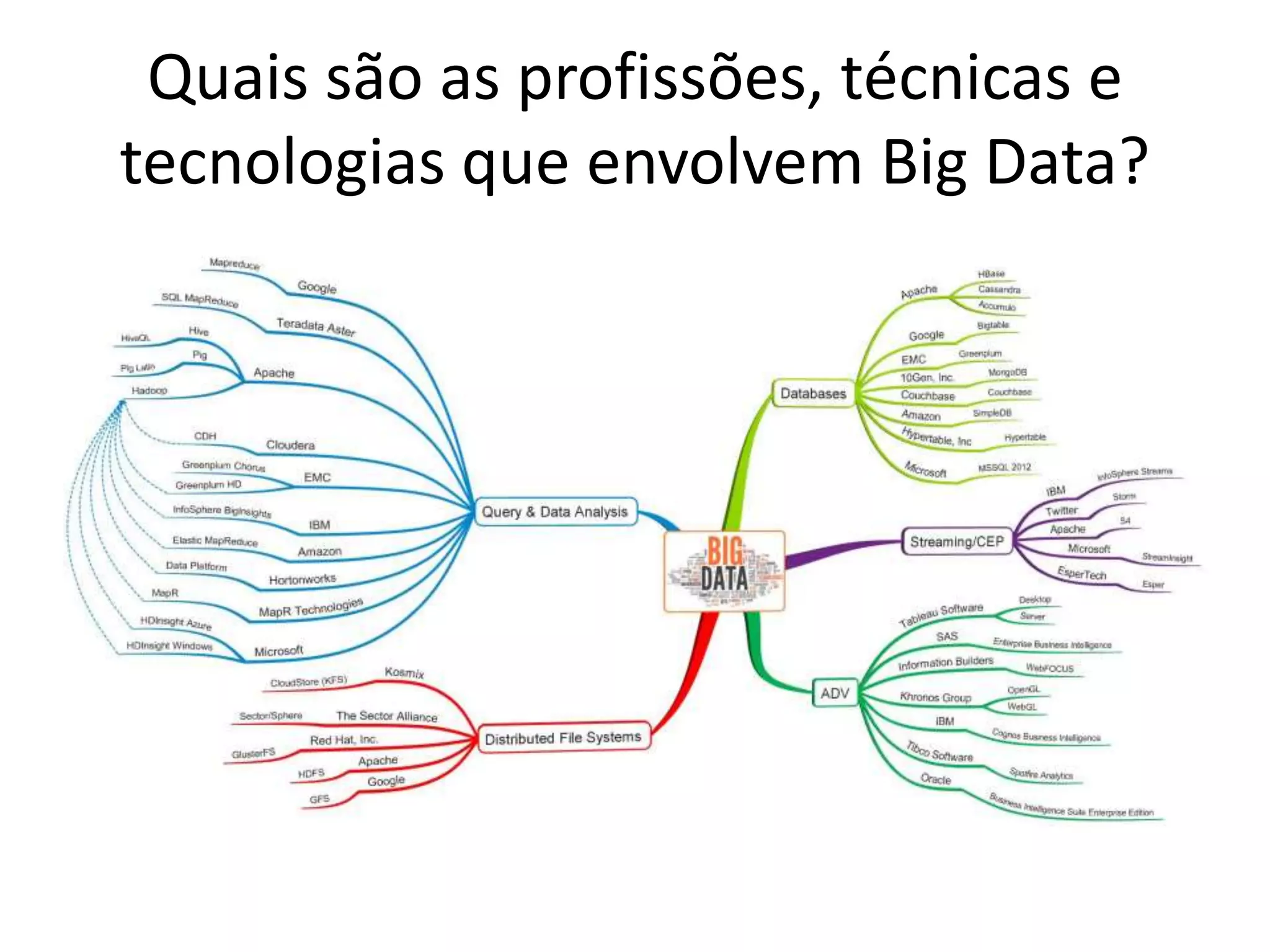

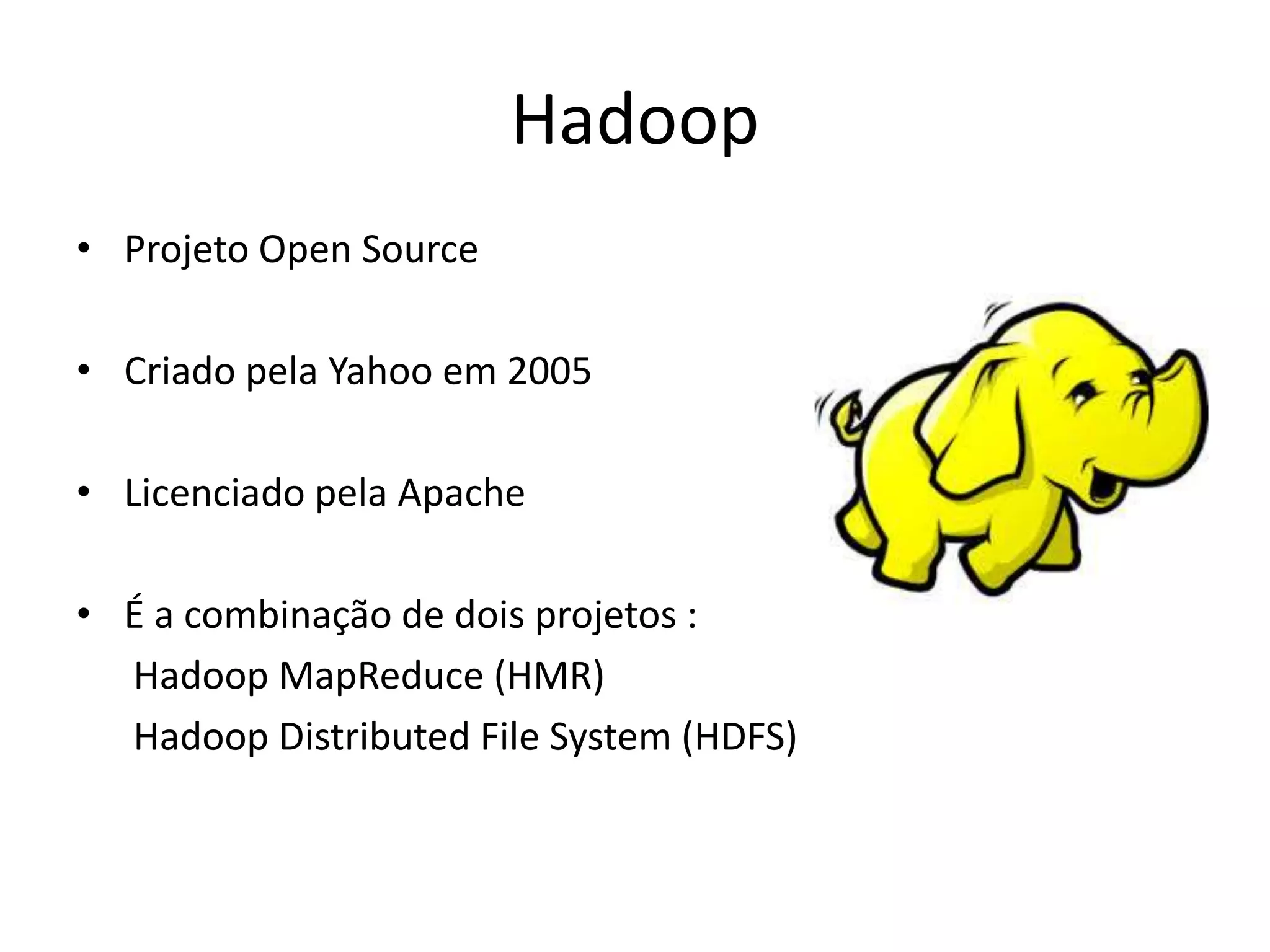

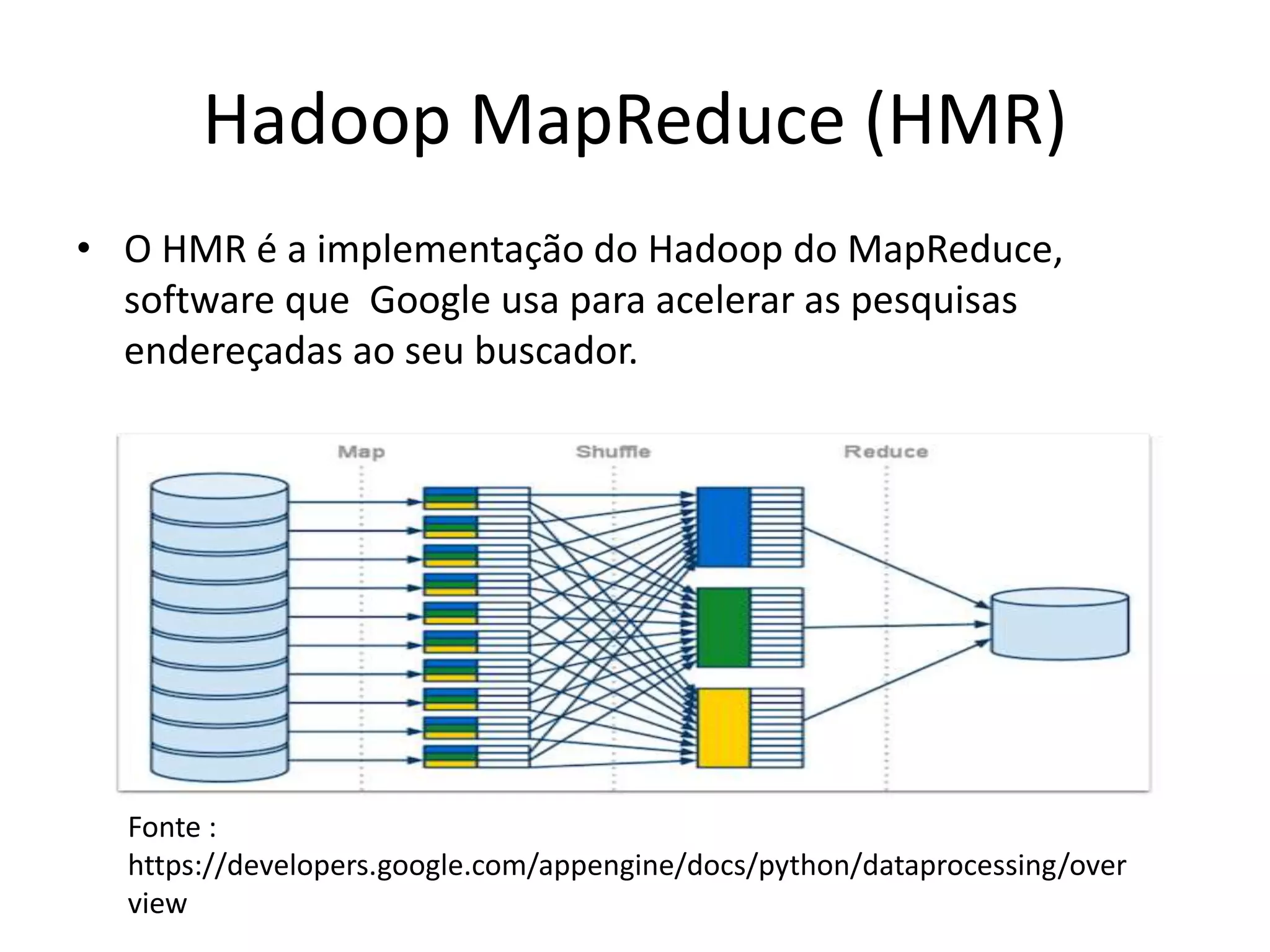
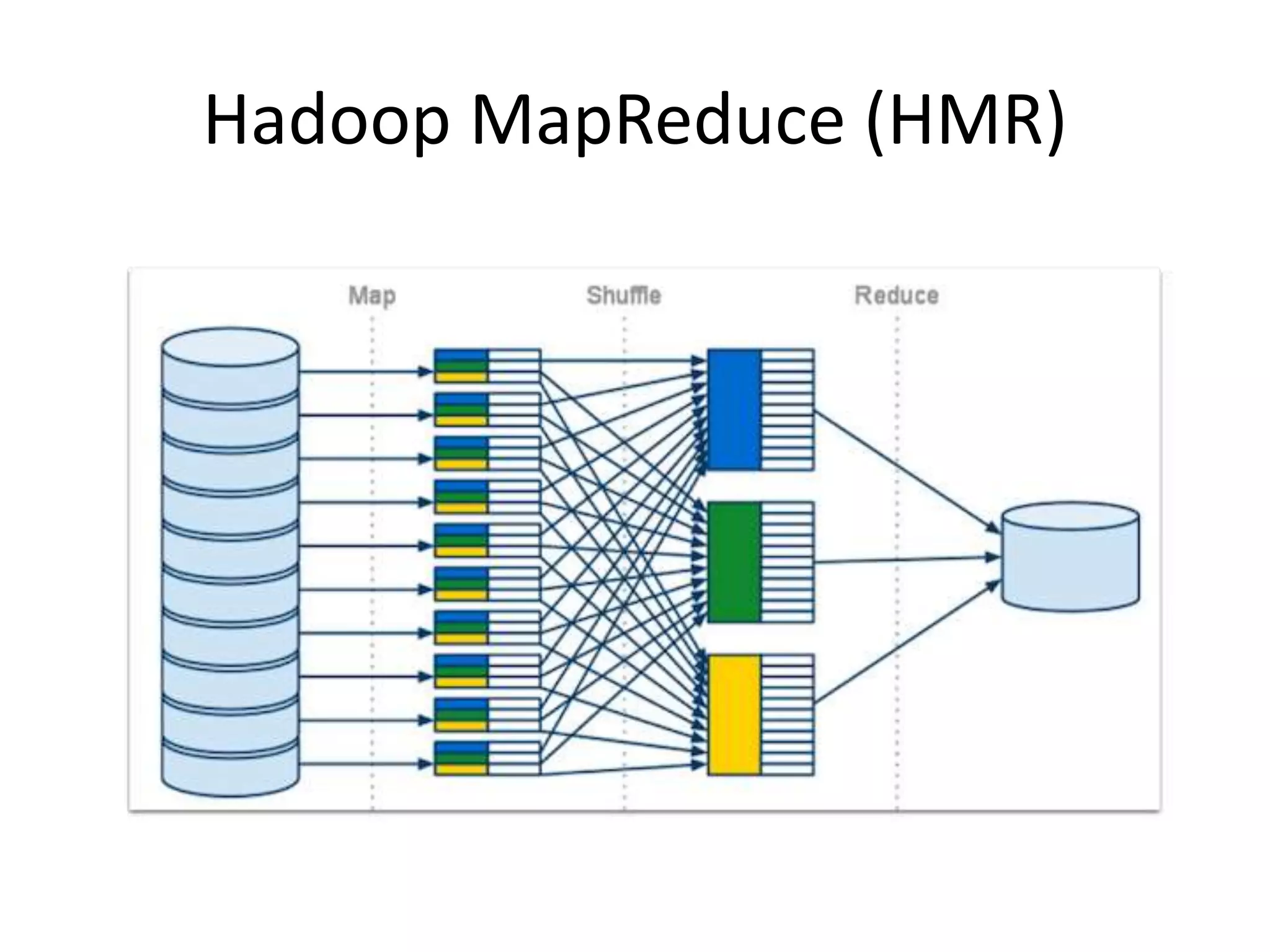
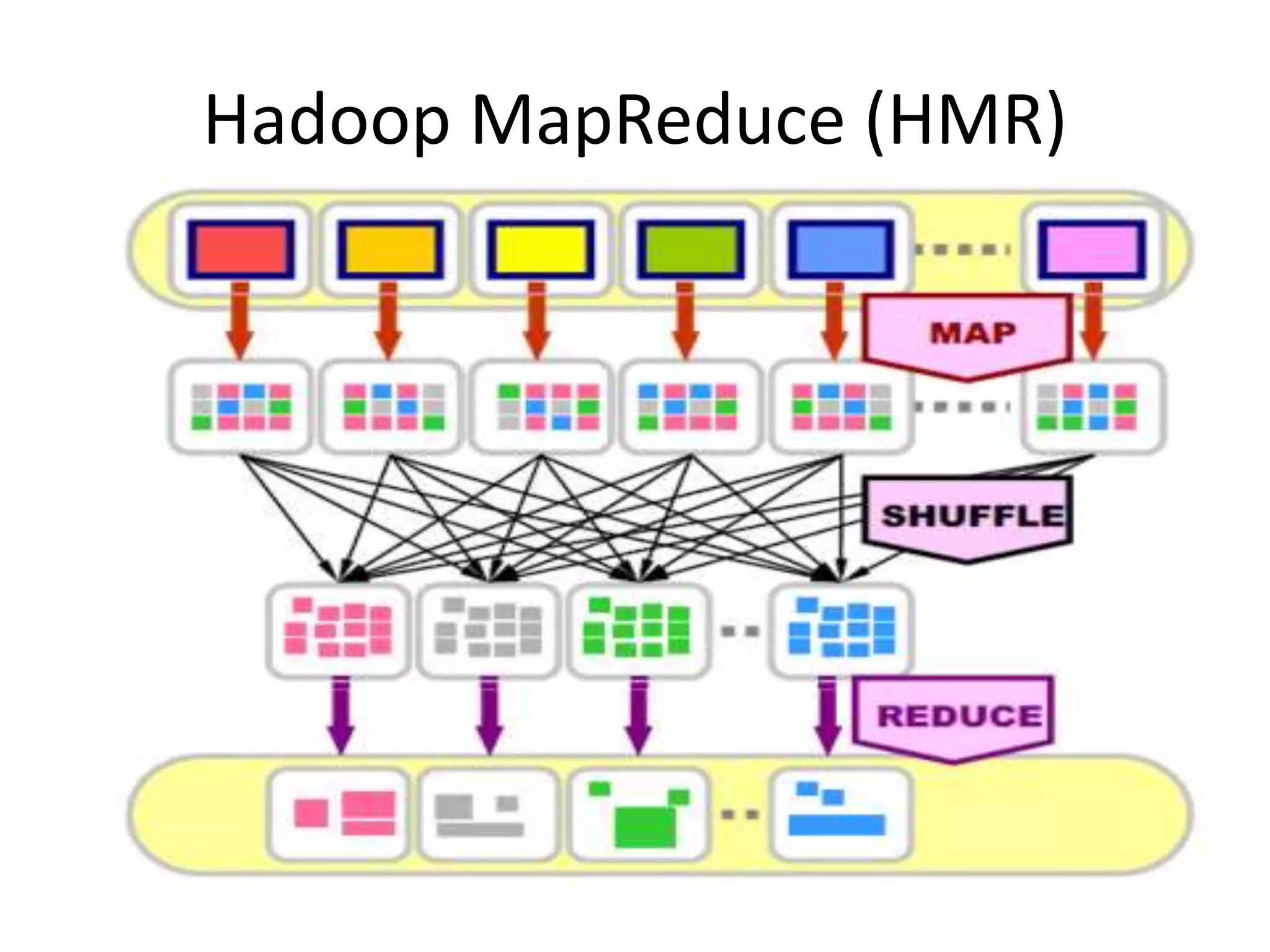
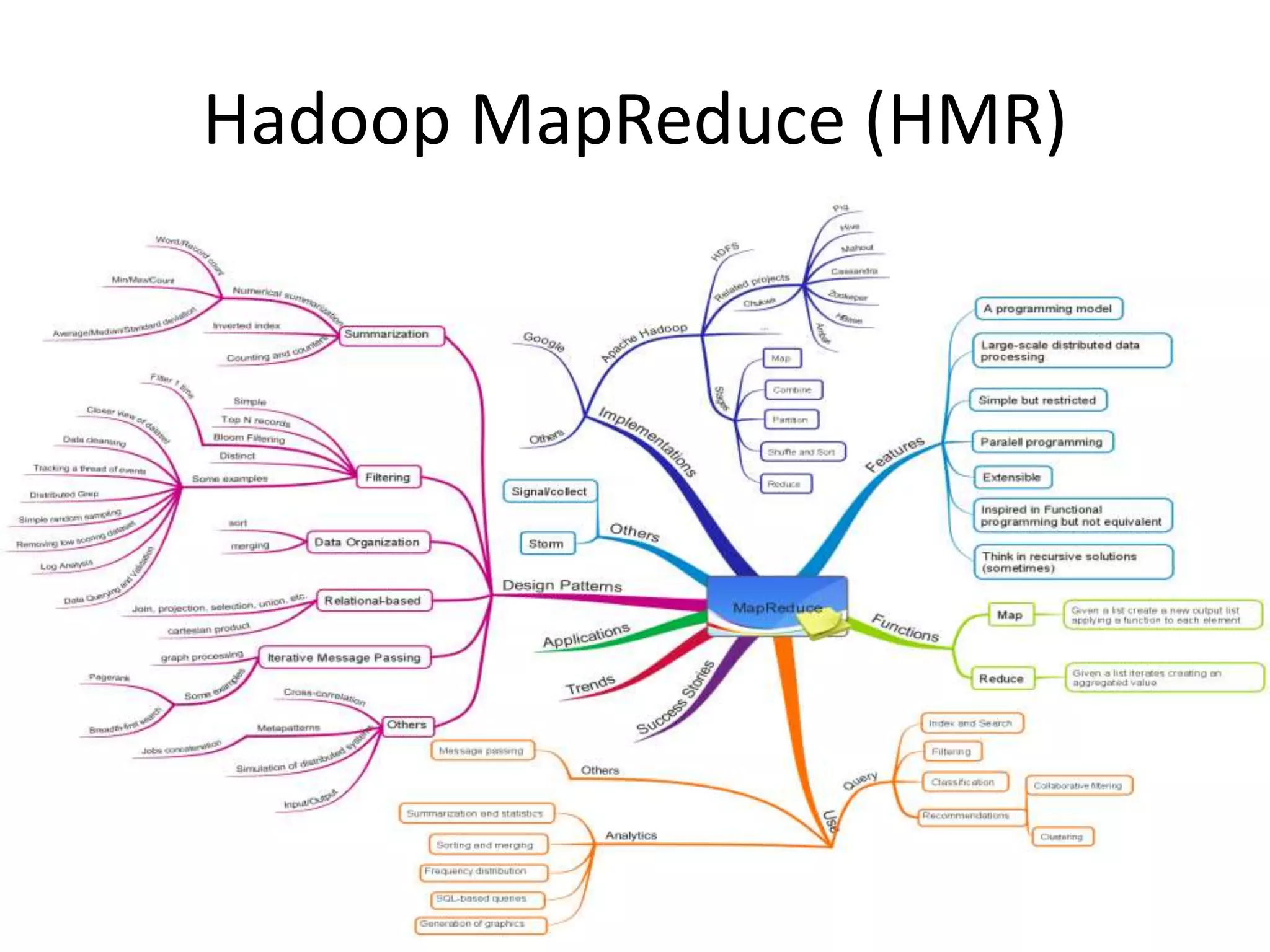

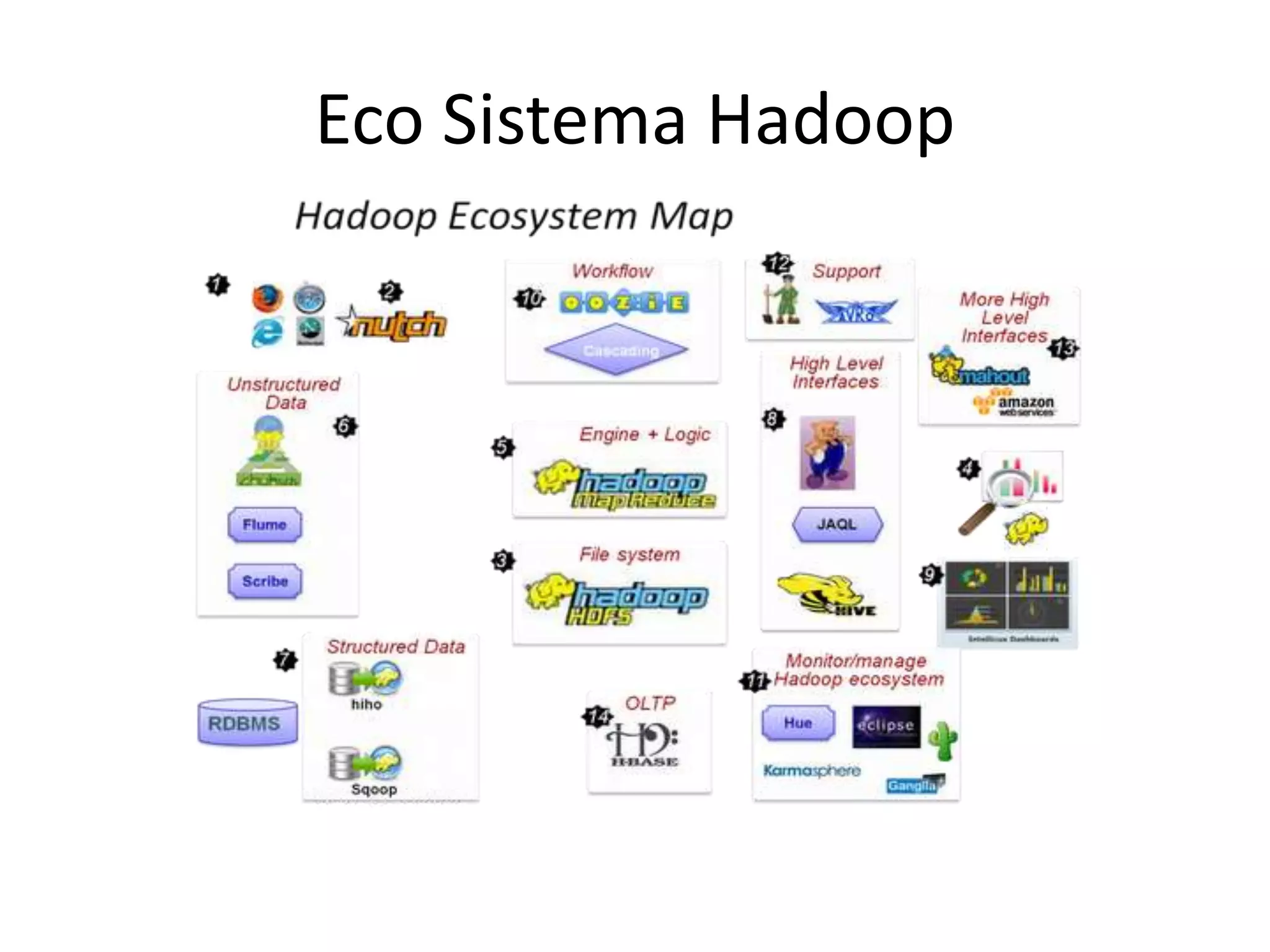
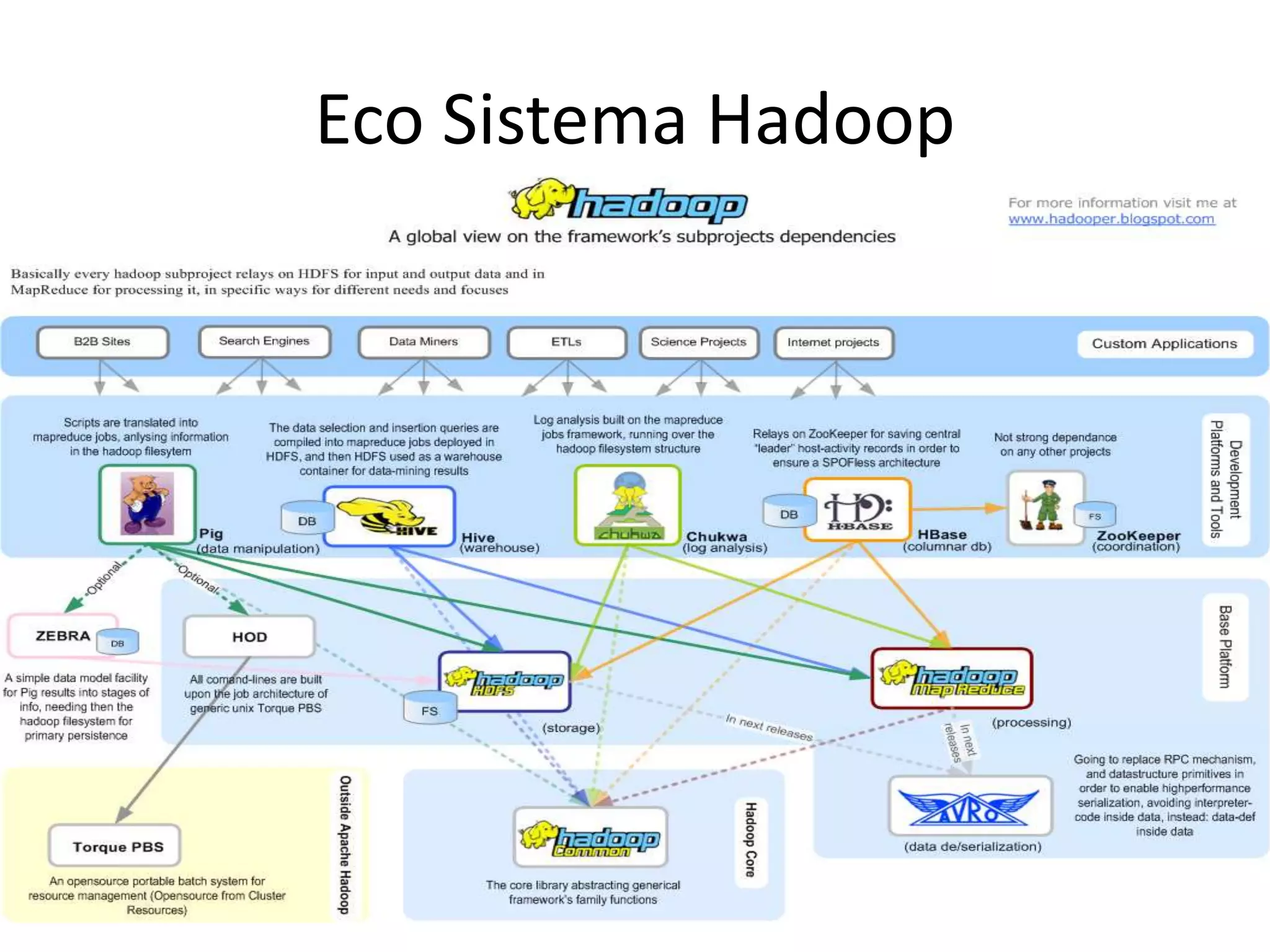













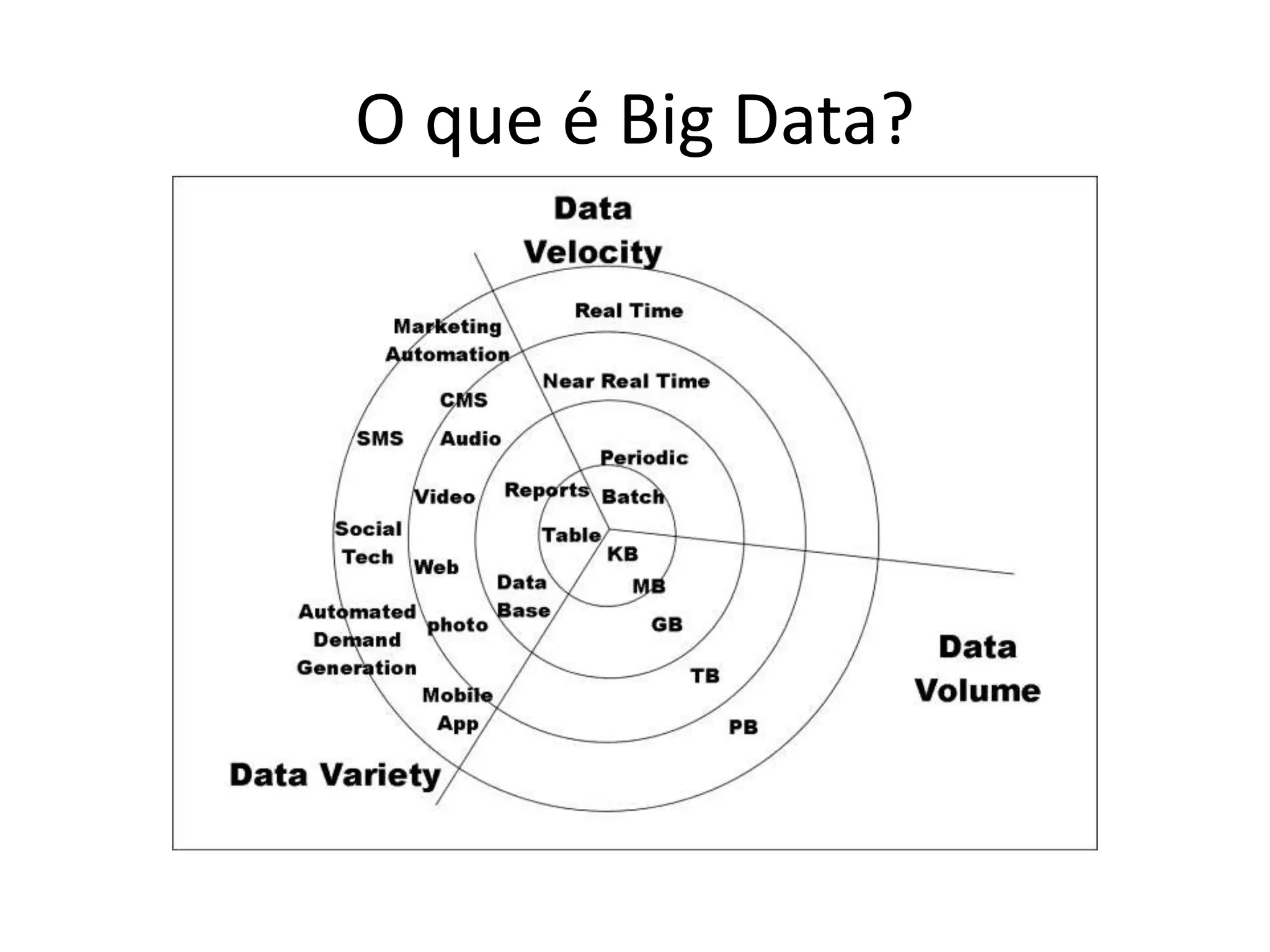
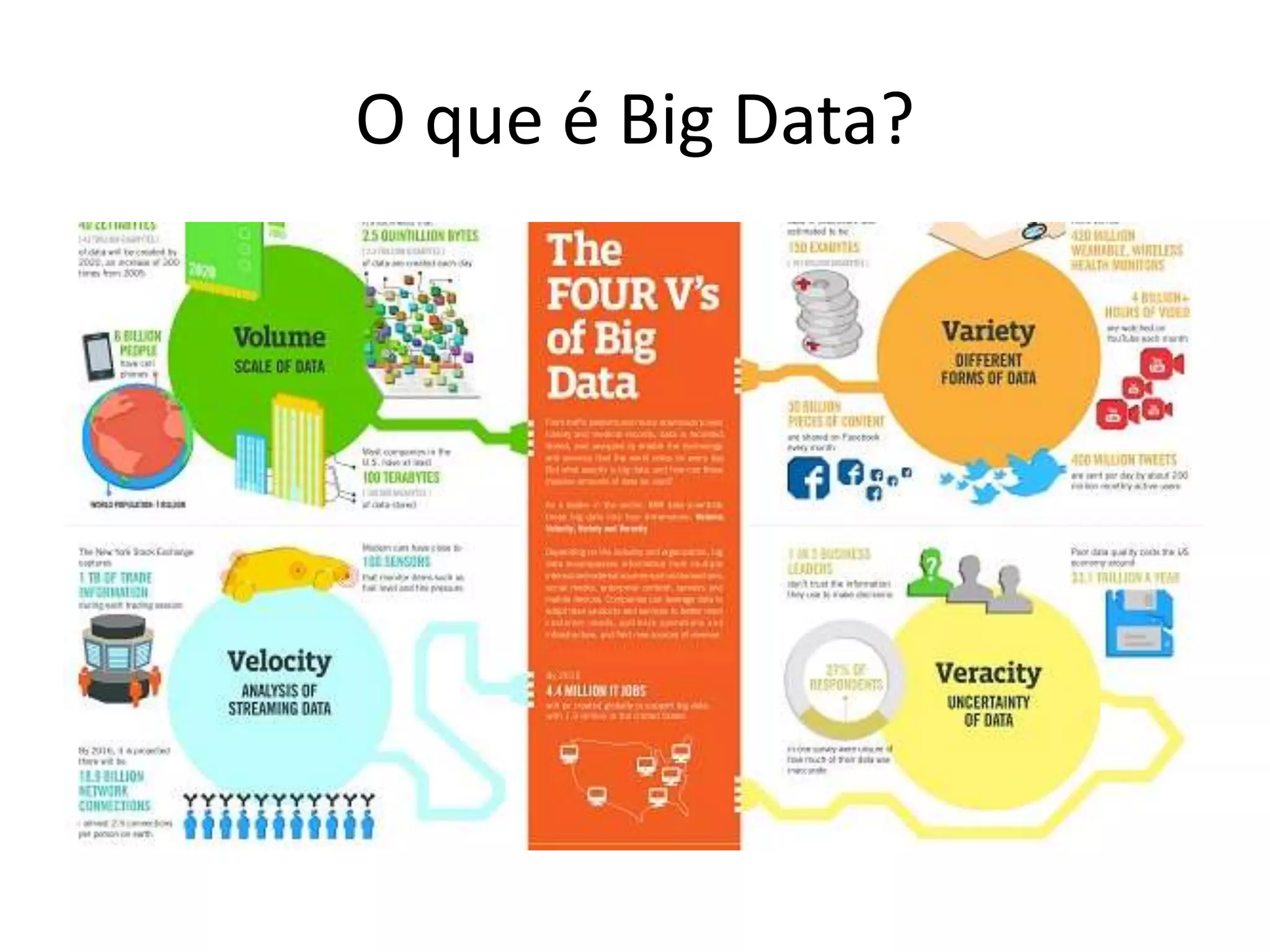


O documento discute as técnicas e tecnologias envolvidas em Big Data, incluindo MapReduce, Hadoop, HDFS, HBase, Mahout e como essas ferramentas podem ser usadas para analisar grandes volumes de dados não estruturados de redes sociais e outras fontes.


















































































