Transferir como PDF, PPTX




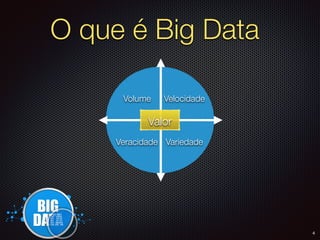
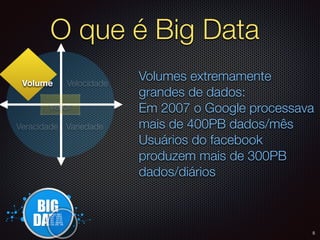
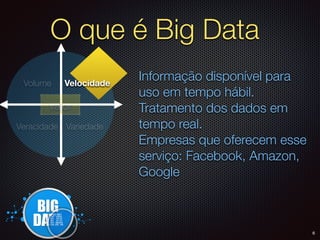
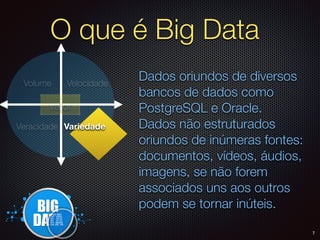
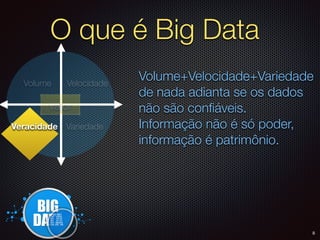
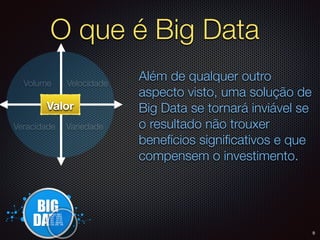












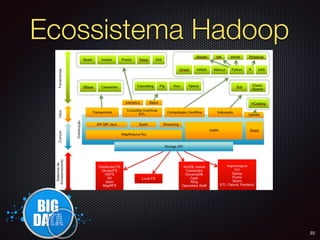







O documento apresenta um resumo sobre Big Data, definindo os conceitos de Volume, Velocidade, Variedade, Veracidade e Valor. Também descreve brevemente como surgiram as primeiras soluções de Big Data na Google e no Hadoop e algumas das principais empresas que utilizam Big Data.















































