Baixado 15 vezes









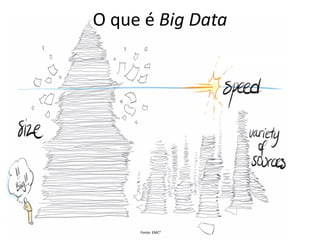
![O que é Big Data
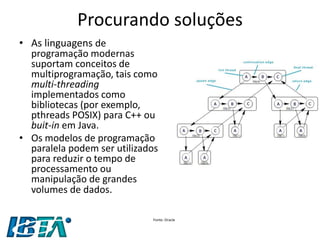
•Segundo o McKinsey Global Institute [2011], Big Data refere-se:
–“ao conjunto de dados cujo tamanho está além da capacidade de análise, captura, armazenamento e gerenciamento de uma ferramenta desenvolvida por um software típico”](https://image.slidesharecdn.com/bigdataparaprogramadoresconvencionaisv2-141124080123-conversion-gate02/85/Big-data-para-programadores-convencionais-9-320.jpg)





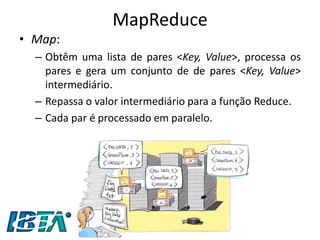
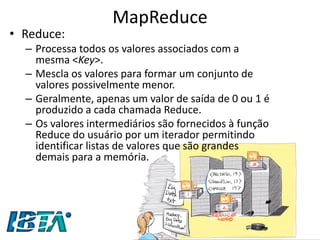
![MapReduce
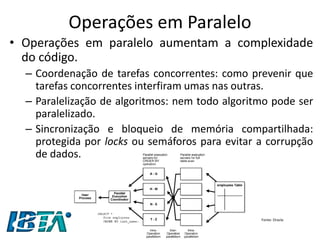
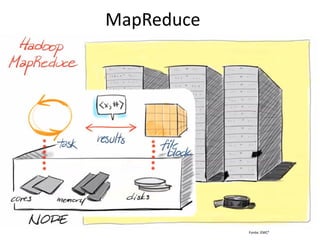
•Segundo a IBM [2009], MapReduce é um
–“Modelo de programação que permite o processamento de dados massivos em um algoritmo paralelo e distribuído, geralmente em um cluster de computadores.”
•MapReduce é baseado nas operações de Map e Reduce de linguagens funcionais como o LISP.
Fonte: IBM](https://image.slidesharecdn.com/bigdataparaprogramadoresconvencionaisv2-141124080123-conversion-gate02/85/Big-data-para-programadores-convencionais-23-320.jpg)





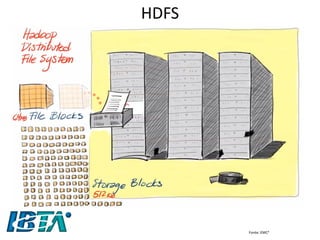

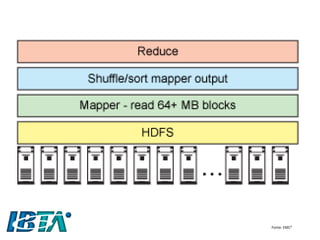
![Hadoop
•Segundo a Hadoop, “Hadoop é um storage confiável e um sistema analítico” [2014]
•Composto por duas partes essenciais:
–o Hadoop Distributed Filesystem (HDFS), sistema de arquivos distribuído e confiável, responsável pelo armazenamento dos dados
–Hadoop MapReduce, responsável pela análise e processamento dos dados.
•O nome do projeto veio do elefante de pelúcia que pertencia ao filho do criador, Doug Cutting.](https://image.slidesharecdn.com/bigdataparaprogramadoresconvencionaisv2-141124080123-conversion-gate02/85/Big-data-para-programadores-convencionais-34-320.jpg)

















O documento discute o projeto Sloan Digital Sky Survey (SDSS), que mapeia o céu e mede distâncias e propriedades de objetos celestes. Os dados do SDSS precisam ser processados rapidamente usando Big Data para direcionar telescópios. O framework Hive é usado para armazenar e analisar os dados do SDSS usando a linguagem HiveQL.







































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)



























