Baixado 17 vezes

















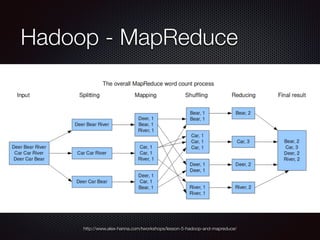

![Hadoop - MapReduce
public
void
map(LongWritable
key,
Text
value,
Context
context)
throws
IOException,
InterruptedException
{
String[]
words
=
value.toString().split("
");
for
(String
word
:
words)
{
context.write(new
Text(word),
new
IntWritable(1));
}
}](https://image.slidesharecdn.com/bigdata-150315163329-conversion-gate01/85/Big-Data-Uma-Introducao-20-320.jpg)

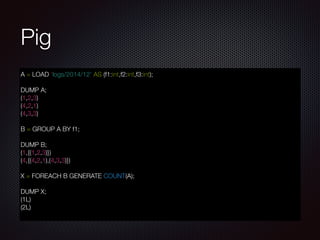



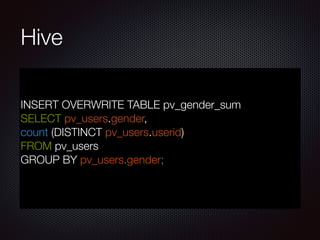











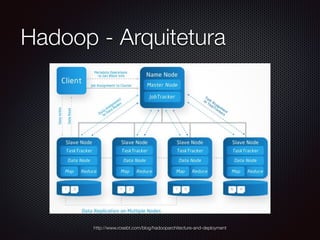
O documento apresenta uma introdução sobre Big Data, abordando o grande volume de dados criados diariamente, os conceitos-chave de Volume, Variedade e Velocidade, e o ecossistema Hadoop, incluindo ferramentas como HDFS, MapReduce, Pig e Hive.



























