Baixado 14 vezes









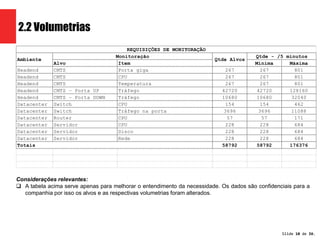
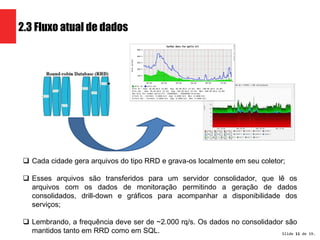


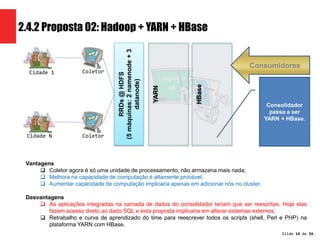
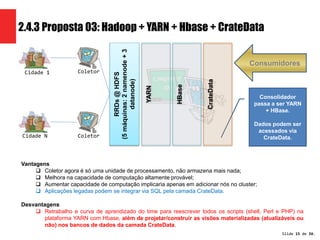






A apresentação propõe três arquiteturas Hadoop para processar dados de monitoramento de rede de uma empresa de telecomunicações. A proposta 3, que usa Hadoop, HBase, YARN e CrateData, é a escolhida por oferecer maior capacidade de processamento e não impactar sistemas legados.
















































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)








