Transferir como ODP, PPTX








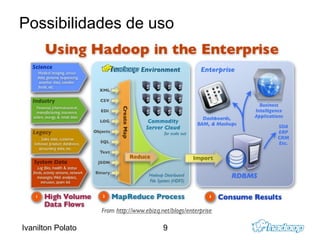













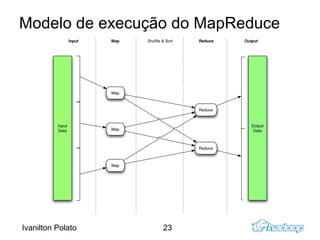


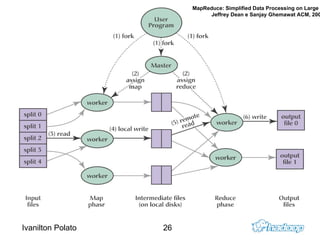
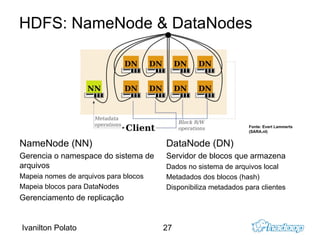



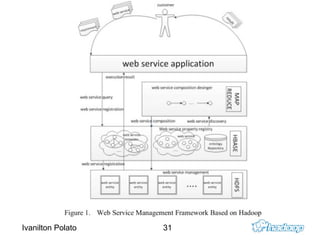


O documento introduz o Apache Hadoop, um framework para computação distribuída em clusters. Ele descreve os principais componentes do Hadoop - HDFS para armazenamento distribuído de dados e MapReduce para processamento paralelo - e explica como eles funcionam juntos para analisar grandes quantidades de dados em clusters.















































