














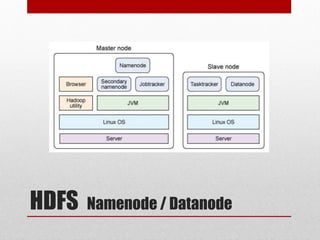
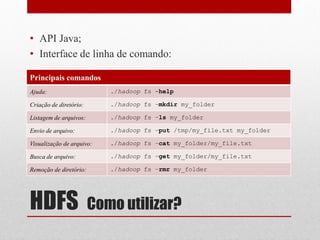



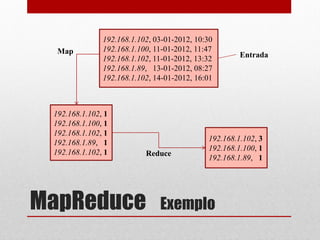





O documento apresenta o Hadoop, um framework Java open-source criado para o processamento de grandes volumes de dados, surgido em 2005 com a colaboração de empresas como Yahoo!. Ele é utilizado em diversas áreas, incluindo astronomia, finanças e redes sociais, e destaca-se pela sua capacidade de análise e redução de custos, sendo adotado por grandes empresas como Google e Facebook. A estrutura do Hadoop inclui componentes como HDFS para armazenamento e MapReduce para processamento, facilitando a execução de tarefas de grandes dados de forma distribuída.



























































![[Engenharia de Software] Marquivos.com](https://cdn.slidesharecdn.com/ss_thumbnails/engenhariadesoftwaremarquivos-com-100701171519-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Engenharia de Software] Marquivos.com](https://cdn.slidesharecdn.com/ss_thumbnails/engenhariadesoftwaremarquivos-com-100701171519-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)