Baixar para ler offline












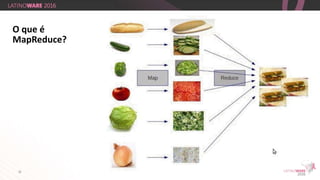
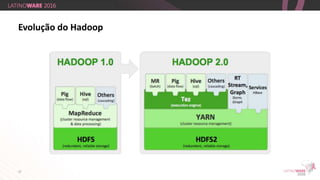
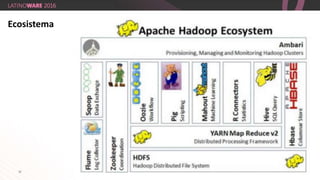



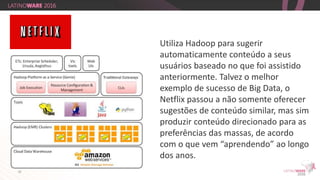










O documento aborda a importância do Big Data e da tecnologia Hadoop na extração de informações valiosas de grandes volumes de dados. Destaca como empresas como Netflix e Eharmony utilizam essas soluções para otimizar suas operações e oferecer experiências personalizadas aos usuários. A apresentação é feita por Thiago Santiago, engenheiro de soluções na Hortonworks, com ênfase nas melhores práticas do mercado de TI.







































































