Transferir como PDF, PPTX





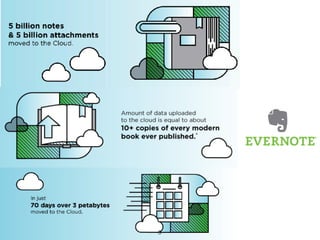




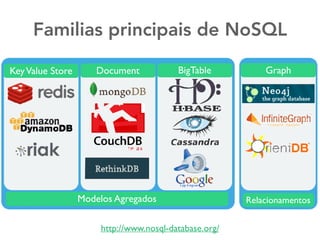



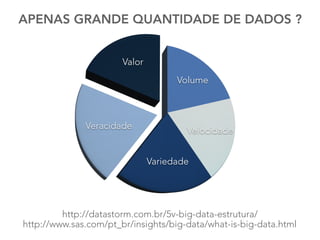
















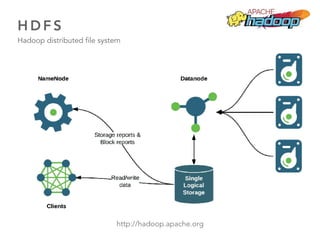
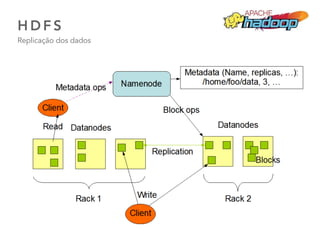


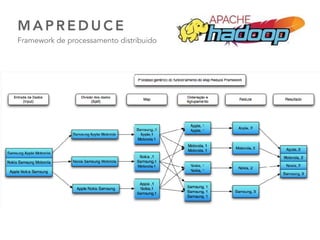

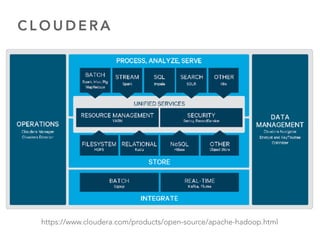








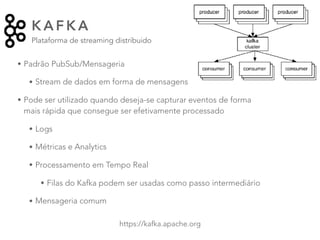






O documento discute as principais ferramentas e aplicações em Big Data, incluindo Apache Hadoop, Spark, Hive, Impala, Kafka e Solr. Ele explica como essas ferramentas podem ser usadas para armazenar e analisar grandes quantidades de dados de forma distribuída.






























![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)




































