Baixar para ler offline

























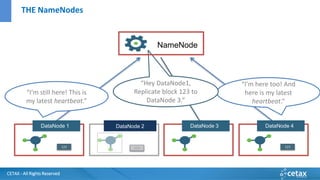
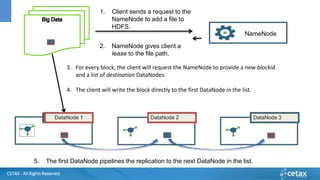
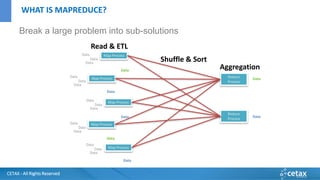

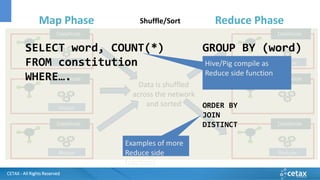





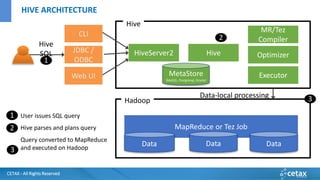


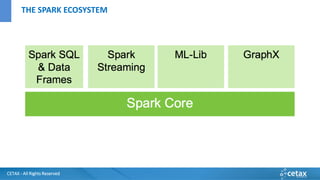




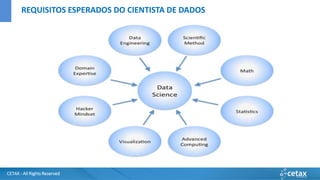











O documento apresenta a CETAX, uma empresa de consultoria e treinamento especializada em business intelligence e data warehouse desde 2000, oferecendo cursos únicos no Brasil. Aborda também o conceito de Big Data, suas características e tecnologias associadas, como Hadoop e Apache Spark, além de discutir o papel do cientista de dados e as competências necessárias para trabalhar com Big Data. O conteúdo destaca a crescente importância dos dados como ativos valiosos e a necessidade de novas abordagens para gerenciá-los e analisá-los.






























































