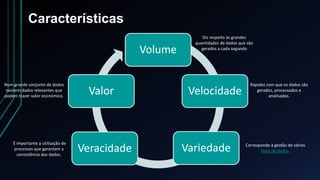
O documento discute o conceito de Big Data, definindo-o como dados caracterizados por grande volume, velocidade e variedade que requerem técnicas específicas para extrair valor. Explora as características do Big Data, tipos de dados, exemplos de fontes de Big Data e técnicas como data mining e machine learning para analisá-lo. Também apresenta tecnologias como NoSQL e Hadoop para armazenar e processar Big Data.