Baixar para ler offline




![1. INTRODUÇÃO AO SOFTWARE SPSS
Tela inicial do SSPS 8.Ofor Windows.
ill] Untilled- SPSS Data Editor · .
--·
I
•/(li V<;r var V(l f var
1
?
?
'
...
5
-
!
I
o
Figura 1: Tela inicial do SSPS 8.0 for Windows.
O pacote estatístico SPSS (Statistical Package for Social
Science - for Windows) é uma das ferramentas disponíveis
para análise de dados utilizando técnicas estatísticas básicas
e avançadas. É um software estatístico de fácil manuseio e é
internacionalmente utilizado há muitas décadas, desde suas
versões para computadores de grande porte.
1.1- BANCO DE DADOS: Definição
Banco de dados é um conjunto de dados registrados em
uma planilha, matriz, com "n" linhas, correspondentes aos
casos em estudo e "p" colunas, correspondentes às variáveis
em estudo ou itens de um questionário.
O número de casos (número de linhas da .
matriz) deve
ser, em geral, maior do que o número de variáveis em estudo
(número de colunas).
4](https://image.slidesharecdn.com/apostiladeestatitica000293883-210415141253/85/Apostila-de-estatitica-000293883-4-320.jpg)





















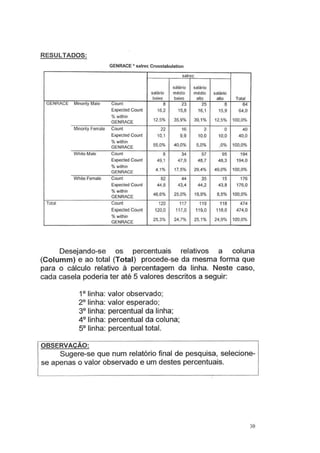

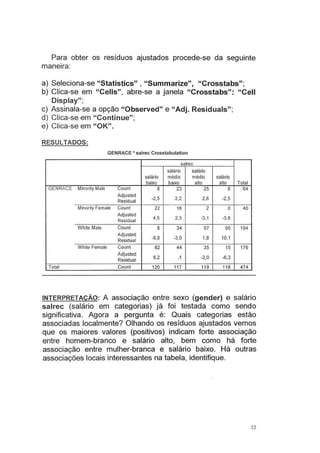

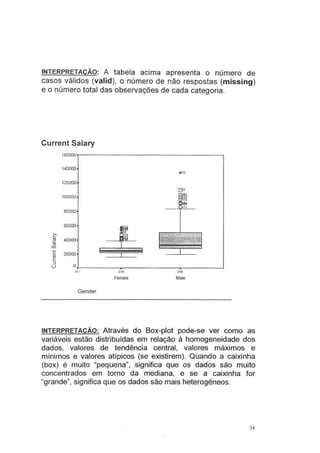


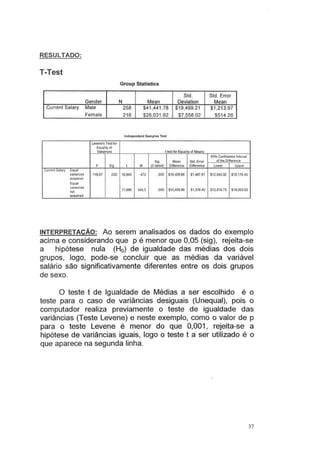












Este documento fornece instruções sobre como utilizar o software estatístico SPSS para análises estatísticas básicas. Ele explica como criar e acessar bancos de dados no SPSS, define variáveis quantitativas e qualitativas, e mostra como categorizar variáveis, obter estatísticas descritivas, criar gráficos e realizar análises univariadas e bivariadas. O documento também aborda testes de comparação de médias e introduz conceitos básicos de análise multivariada.



















































































