Baixado 13 vezes













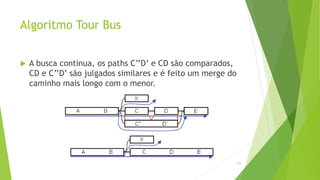
![Grafos De Bruijn
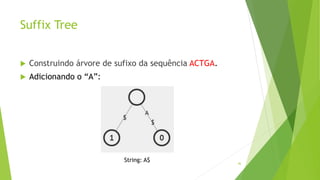
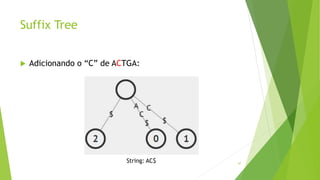
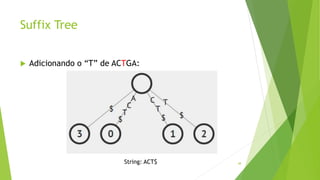
k-mer é uma substring de tamanho k.
Exemplo de string: GGCGATTCATCG
Se k = 4, temos os 4-mers: GGCG, GCGA, CGAT ...
Se k = 3, temos os 3-mers: GGC, GCG, CGA ...
Como gerar todos os k-mers em Python:
[s[i:i+k] for i in range(len(s)) if len(s[i:i+k]) == k]
“s” é a string e “k” é o tamanho da substring.
14](https://image.slidesharecdn.com/velvetassembler-151030152517-lva1-app6891/85/Velvet-assembler-14-320.jpg)
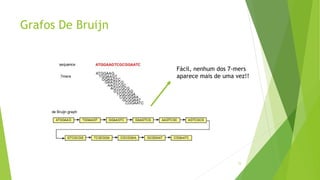
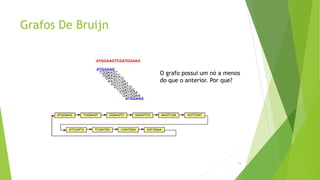

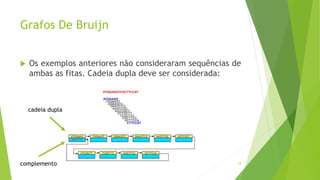
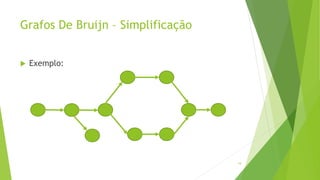
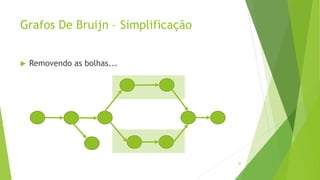

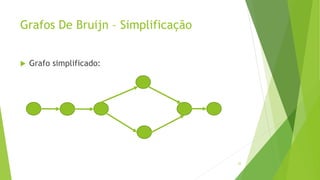




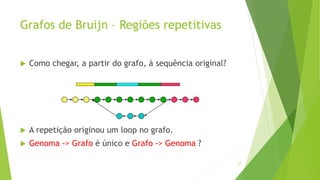


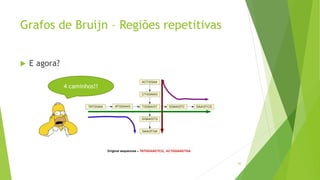

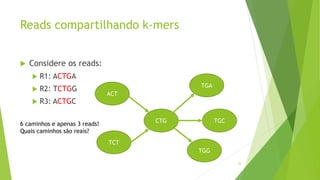

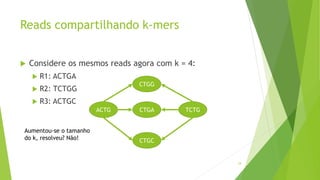

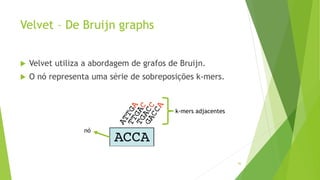
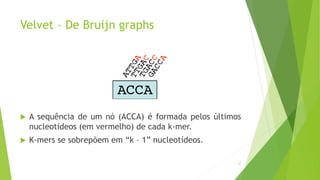
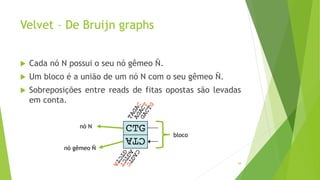
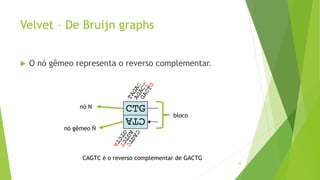
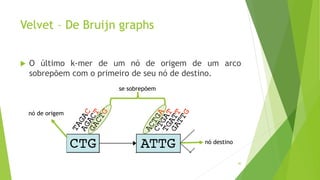
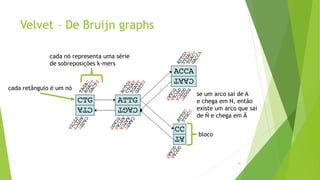




































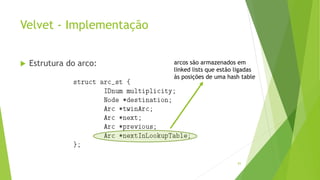
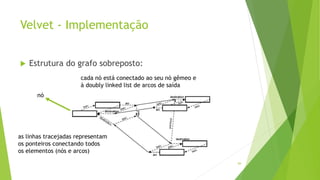





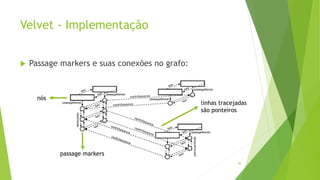




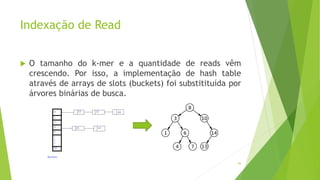

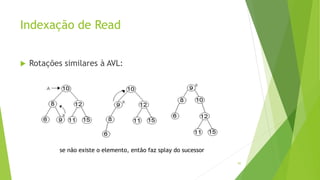


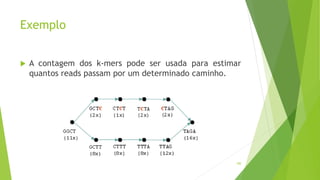





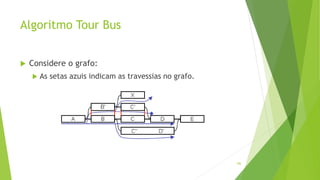

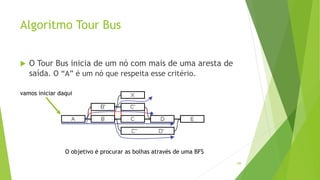

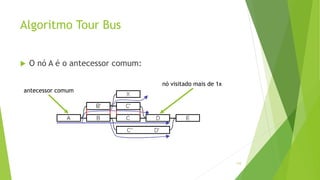
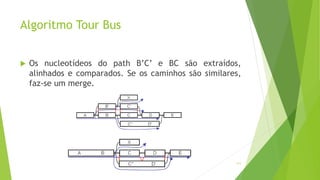







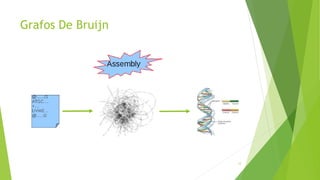
Velvet é um assembler gratuito em C projetado para montar short reads produzidos por tecnologias de sequenciamento de nova geração. Ele utiliza um grafo de Bruijn para representar os dados, no qual cada nó representa uma série de k-mers sobrepostos. Velvet simplifica o grafo removendo nós desnecessários e utiliza propriedades dos caminhos no grafo para montar contigs a partir das sequências originais.
























































