O documento discute estratégias de mapeamento de herança em frameworks ORM, incluindo single table, joined e table per class. Ele também cobre callbacks e caches no JPA.
Programação Orientada aObjetos
Estudo de Frameworks
(Mapeamento Objeto-Relacional em Java)
Objetivo: Identificar os processos de
mapeamento Objeto-Relacional
Prof. Nécio de Lima Veras
Estratégias
• SINGLE_TABLE
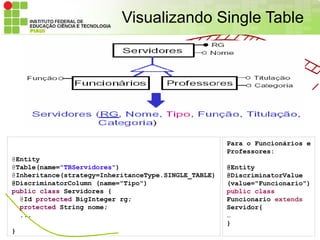
– É a opção default. Há uma única tabela para toda a herarquia de classes.
– Há uma coluna na tabela para determinar a classe (DiscriminatorColumn);
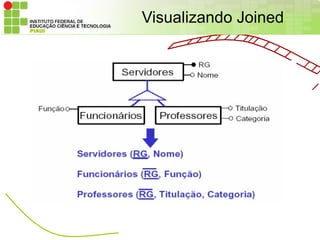
• JOINED
– Define que há uma tabela para cada classe da hierarquia de classes.
– Atributos de uma superclasse são persistidos na tabela da superclasse;
– Assim, para obter um objeto de uma subclasse, é necessário fazer um join
envolvendo todas as tabelas das superclasses. Isso pode ser bastante
oneroso para o banco de dados e comprometer a performance da
aplicação, especialmente quando a hierarquia é complexa e composta
de muitas classes;
– Há uma coluna na tabela da classe base para determinar a classe
(DiscriminatorColumn);
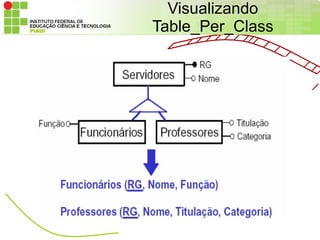
• TABLE_PER_CLASS
– Semelhante à estratégia JOINED, mas cada tabela possui os campos dos
atributos herdados e os campos dos seus próprios atributos (não herdados);
4.
Visualizando Single Table
Para o Funcionários e
Professores:
@Entity
@Table(name="TBServidores") @Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE) @DiscriminatorValue
@DiscriminatorColumn (name="Tipo") (value="Funcionario")
public class Servidores { public class
@Id protected BigInteger rg; Funcionario extends
protected String nome; Servidor{
... …
}
}
Observações
• É possíveldeterminar uma superclasse da qual
uma entidade herda atributos persistentes
através da anotação @MappedSuperclass;
• Recurso interessante quando várias classes
compartilham atributos persistentes;
• Pode-se usar as anotações
@AttributeOverride ou
@AssociationOverride na subclasse para
sobrescrever a configuração da superclasse;
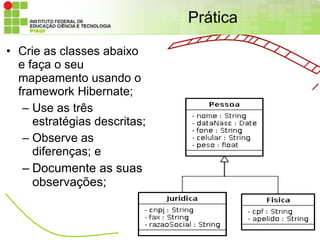
Prática
• Crie asclasses abaixo
e faça o seu
mapeamento usando o
framework Hibernate;
– Use as três
estratégias descritas;
– Observe as
diferenças; e
– Documente as suas
observações;
Callbacks
• JPA permitemétodos de callback para
acessar o EntityManager.
• Eventos disponíveis:
– PostLoad
– PrePersist
– PostPersist
– PreRemove
– PostRemove
– PreUpdate
– PostUpdate
11.
Exemplos
@PrePersist
void validateCreate() {
if (idade > 130) {
throw new IllegalStateException();
}
}
@Entity
@EntityListeners(br.cefetpi.Monitor.class)
Método public class Pessoa {
...
Callback em }
classe public class Monitor {
@PostPersist
Listener public void alertaNovaPessoa(Pessoa p) {
emailRH(p);
}
}
12.
Sugestão de Prática
•Dadas as classes do exercício anterior, faça os seguintes
callbacks:
– Informe quando uma pessoa for carregada;
– Antes de gravar uma pessoa (física e jurídica), verifique
se os documentos estão preenchidos;
– Após uma pessoa ter sido gravada, exiba o documento
correspondente;
– Antes de remover uma pessoa, pergunte se essa é
realmente a intenção. Caso não seja, gere uma exceção;
– Após a remoção de uma pessoa, informe o documento
no qual foi removido;
– Após de realizar uma alteração em uma pessoa, para
efeito comparativo, mostre os documento antigo e novo;
Cache
• O Hibernate trabalha com dois tipos de cache:
– first-level-cache – cache simples de sessão que é utilizado
sempre, exclusivamente para diminuir os acessos ao banco de
dados. Ao invés de realizar atualizações a cada comando dentro
de uma transação, as atualizações são feitas somente ao final da
transação.
• Exemplo: Se um objeto é modificado várias vezes dentro de
uma transação, o Hibernate gera somente um único comando
SQL UPDATE ao final da transação, contendo todas as
modificações.
– second-level-cache – Mantém os objetos em memória e os
utiliza mesmo entre diferentes sessões de uma mesma session
factory.
• Não é usado por default, devendo ser explicitamente
configurado para que possa ser usado.
• Deve-se configurar que entidades vão usá-lo, ou seja, quais
vão ficar no cache.
15.
Visualizando
• Existemdiferentes estratégias para o Cache.
– Indicamos que tipo de leitura e/ou escrita será feita e o
cache saberá quando invalidar uma entrada;
– As estratégias são essas:
• NONE
• NONSTRICT_READ_WRITE
• READ_ONLY
• READ_WRITE
• TRANSACTIONAL
@Entity
@Cache(usage=CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public class Cliente {
...
}
16.
Entendendo as Estratégias
•READ_ONLY
– Útil para dados que são lidos, mas não, atualizados.
– Simples e com excelente perfomance. A melhor em relação
às demais.
• READ_WRITE
– Usado quando os dados são mais lidos que alterados.
– Tem mais overhead que caches read-only.
• NONSTRICT_READ_WRITE
– Não garante que duas transações não modificarão
simultaneamente o mesmo dado.
– Usado quando as alterações são poucas;
• TRANSACTIONAL
– Cache inteiramente transacional, que exige um ambiente
com suporte à JTA.