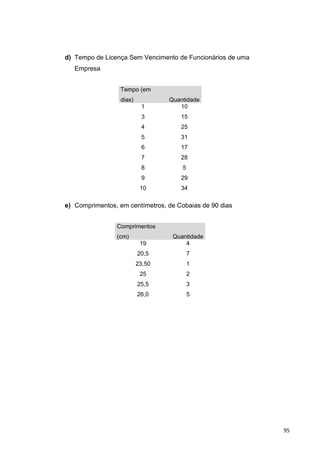
Baixado 90 vezes








































![Para uma confiança de 99%, Z = 3
n = (32
. 50 . 50) / 42
= 1406,25 = 1406 estudantes.
Assim, o resultado obtido significa que o tamanho da amostra deve ser
pelo menos 1406 estudantes, para oferecer segurança de probabilidade de
99% de resultados válidos para o universo e de 4% de erro admitido.
Exemplo 2:
Suponha-se que a pesquisa sobre as atitudes dos estudantes
universitários seja realizada na Paraíba, onde os resultados não passam de
50.000. Além disso, o pesquisador quer trabalhar apenas com um nível de
confiança de 95% e um erro de amostragem de 4%. Qual é o tamanho da
amostra, com essas exigências? Considerando que o universo é menor que
100.000 estudantes, utiliza-se a fórmula para universos finitos:
n = [Z2
. P . Q . N] / [E2
. (N – 1) + Z2
. P .Q]
Onde N é o tamanho da população.
Cálculo:
Para uma confiança de 95%, Z = 2
n = [22
. 50 . 50 . 50.000] / [16 . (50.000 – 1) + 22
. 50 .50] = 617,3 = 617
estudantes.
41](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-41-320.jpg)




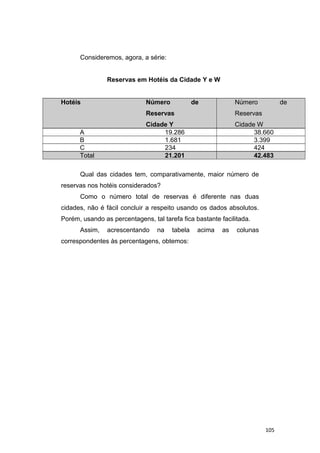
![Base da Amostra:
Áreas Estratos Populacionais
Construção Civil 1000
Financeira 2000
Alimentação 3000
Comércio 4000
Total 10.000
1o
) Determinação do tamanho proporcional dos estratos:
Áreas Cálculos Estratos Amostrais
Construção Civil 1000/10000 10%
Financeira 2000/10000 20%
Alimentação 3000/10000 30%
Comércio 4000/10000 40%
Total ─── 100%
2o
) Tamanho Global da amostra:
n = [22
. 50 . 50 . 10.000] / [16 . (9.999) + 22
. 50 .50] = 588
46](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-46-320.jpg)












































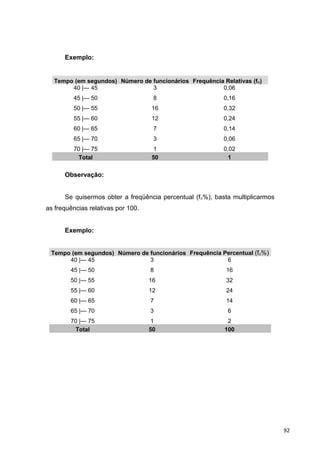











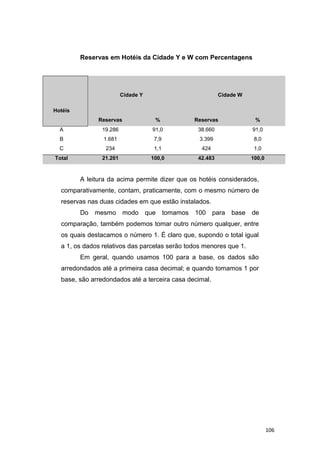














![3)Distribuição por Intervalo de Classe
‘Desempenho de Funcionários no Treinamento de uma Tarefa ’
Notas fi xi xifi di difi
20 |—| 29 2 24,5 49.0 -4 -8
30 |—| 39 9 34,5 310.5 -3 -27
40 |—| 49 11 44,5 489.5 -2 -22
50 |—| 59 15 54,5 817.5 -1 -15
60 |—| 69 17 64,5 1096.5 0 0
70 |—| 79 16 74,5 1192.0 1 16
80 |—| 89 7 84,5 591.5 2 14
90 |—| 99 3 94,5 283.5 3 9
Total 80 ─── 4830 ─── -33
Pelo Processo Longo:
X = Σxifi X = 4830/80 = 60,4
n
Pelo Processo Breve:
X = x0 +h [Σdifi] X = 64,5 + 10[-33] = 60,4
n 80
Onde:
─
xo = ponto médio da classe em que o di é igual à zero.
2ª) Mediana (Me):
123](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-123-320.jpg)



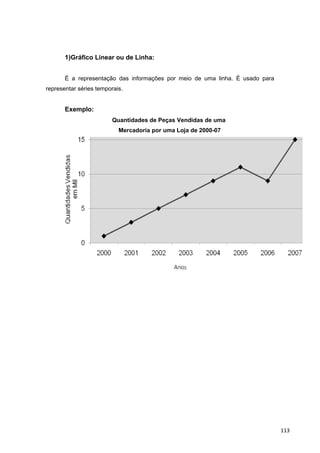
![5)
‘Estatura de 40 Candidatos a Cargos de Garis da COMLURB’
Estatura(cm
)
Fi Faci
150 |— 154
154 |— 158
158 |— 162
162 |— 166
166 |— 170
170 |— 174
4
9
11
8
5
3
4
13
5) 20 < 24, Classe da Me
32
37
40
Σ 40 -
Processo de Cálculo:
1º) Calculam-se as Fac’s
2º) Calcula-se o EMe
3º) Identifica-se a classe da mediana tal que:
4º) Aplica-se a fórmula:
Me = li + h [ EMe – ‘FAC ]
fmed
EMe ≤ Faci
127](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-127-320.jpg)
![Onde :
Me = mediana.
Li = limite inferior da classe da mediana.
H = intervalo de classe.
EMe =elemento mediano.
‘Fac = 128reqüente128 acumulada anterior à classe da mediana.
Fmed = freqüência absoluta da classe da mediana.
EMe = 40/2 = 20
Me = li + h [ EMe – ‘FAC ]
fmed
Me =158 + 4[ 20 – 13 ] = 160,5
11
3ª) Moda ( Mo)
É o valor que possui a maior freqüência em um conjunto de dados ou
distribuição.
Exemplos:
1) 7,8,9,10,10,10,11,12,13 e 15
Mo = 10
2) 3,5,8,10,12,13
Não há – distribuição amodal
128](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-128-320.jpg)


![1ª) Moda bruta: É o ponto médio da classe modal.
Então: Mo = (700+900)/ 2 = R$ 800,00
2ª) Moda de king:
Mo = li + h [ fpost ]
────────────
fant + fpost
M0 =700 + 200 [ 15 ] = R$ 790,9
──────
18+15
3ª) Moda de Czuber:
Mo = li + h [ f.máx. – f.ant. ]
──────────────────
2.fmáx – (f.ant + f.post.)
Mo = 700+ 200 [ 31– 18 ]
──────────────────
(2 x 31) – (18 + 15)
Mo = R$ 789,7
131](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-131-320.jpg)





![EQ1 = 1 x 84 = 21
4
Q1= li + h [ EQ1 – ‘Fac ]
────────────
FQ1
Q1= 700 + 200 [ 21 – 15 ]
──────── = R$ 728,00
43
EQ3 = 3 x 84 = 63
4
Q3= li + h [ EQ3 – ‘Fac ]
FQ3
Q3= 900 + 200 [ 63 – 58 ] = R$ 956,00
────────
18
Faixa Salarial: R$ 728 a R$ 956
2ª) Os Percentis (Pi):
Denominamos percentis os 99 valores que separam a série em 100
partes iguais.
Indicamos:
P1,P2,........P32..........,P99
É evidente:
137](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-137-320.jpg)
![P50 = Me = Q2; P25 = Q1 ; P75 = Q3
Faixa que concentra a maior parte dos valores:
P25 a P75
Se 20% dos funcionários com menores salários recebem cesta básica
pela empresa, qual o maior salário para recebimento desse benefício?
Solução:
EP20 = in = 20 x 84 = 16,8
100 100
Pi= li + h [ EPi – ‘Fac ]
FPi
P20 = 700 + 200 [ 16,8 – 15 ] = R$ 708,00
43
Medidas de Dispersão:
Objetivo:
Caracterizar se os valores da distribuição são homogêneos ou
heterogêneos.
1ª) Amplitude Total (R):
Chamando:
Xmax = maior valor da distribuição
138](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-138-320.jpg)





![Processo Breve:
S2
= [Σ d2
i fi - (Σdi fi)2
] x (h2
/n)
n
Então:
S2
= [66 - (6)2
] x (22
/44) = 5,93
44
3ª) Desvio Padrão(S):
É raiz quadrada da variância, definida para que a medida de
variabilidade fique na mesma escala da variável original.
Então dos exemplos anteriores temos:
S = √1,17 = 1,08
S = √2,33 = 1,53
S = √5,93 = 2,44
144](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-144-320.jpg)







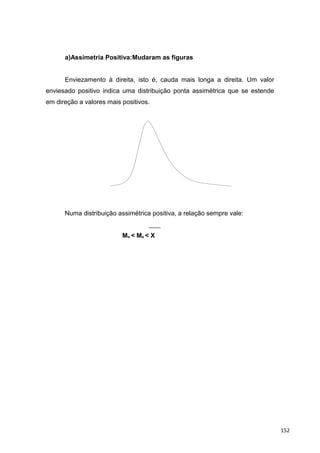
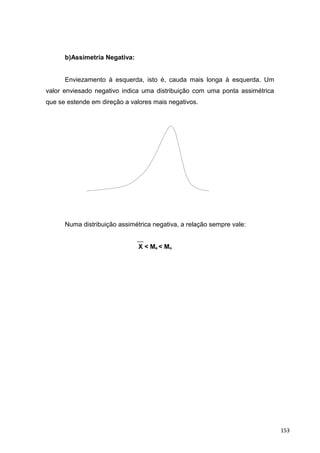
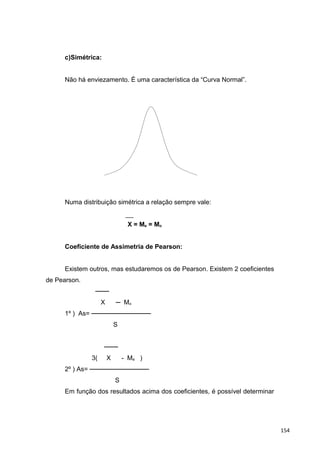



![Coeficiente Momento de Assimetria(MAS):
n
MAS = ──────────── . M3
(n-1)(n-2)
Tem-se que:
n ──
M3 = [Σ( Xi – X)3
/ S3
]
i=1
1º) Se:
MAs = 0, a distribuição é simétrica.
MAs > 0, a distribuição é assimétrica positiva.
MAs < 0, a distribuição é assimétrica negativa.
2º) Se:
/ MAs / ≤ 0,15, distribuição praticamente simétrica.
0,15 < / MAs / ≤ 1, assimetria moderada.
/ MAs / > 1, forte assimetria.
158](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-158-320.jpg)



![Exemplo 2: Vamos calcular o MAS:
Declarações de Despesas feitas pelos Executivos de uma
Empresa
(Em 100 Reais)
Classes
Fi xi
──
[(x – xi) / s ]3
──
[(x – xi) / s ]3
fi
00 |— 15 12 7,5 - 3,58 - 42,96
15 |— 30 23 22,5 - 0,59 - 13,57
30 |— 45 26 37,5 0,00 0,00
45 |— 60 18 52,5 0,16 2,88
60 |— 75 13 67,5 1,90 24,70
75 |— 90 8 82,5 7,20 57,65
Total 100 ── ── 28,65
Solução:
Neste caso, quando a distribuição vem em intervalo de classe
deveremos fazer umas modificações em M3:
n ──
M3 = [Σ( xi – X)3
/ S3
] fi
i=1
Onde:
xi = ponto médio da classe i;
fi = freqüência simples da classe i.
162](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-162-320.jpg)




![Coeficiente Momento de Curtose (Mk):
Neste coeficiente, a curtose positiva indica uma distribuição
relativamente em cume. A curtose negativa indica uma distribuição
relativamente plana. A curtose será definida da seguinte forma:
n(n+1) 3(n-1)2
MK= [ ─────────── . M4 ] ─ [ ──────── ]
(n-1)(n-2)(n-3) (n-2)(n-3)
Tem-se que:
n ──
M4 = [Σ( Xi – X)4
/ S4
]
i=1
Neste caso, se:
MK=0 , distribuição mesocúrtica
MK>0, distribuição leptocúrtica
MK< 0, distribuição platicúrtica
Observação:
Tanto o MAS quanto o MK podem ser obtidos diretamente na planilha
eletrônica Excel na função inserir função e nas opções “Distorção” e na
função “Curt” para assimetria e curtose respectivamente. A estatística de
Bera-Jarque não está disponível diretamente no Excel.
167](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-167-320.jpg)


![n(n+1) 3(n-1)2
MK= [ ─────────── . M4 ] ─ [ ──────── ]
(n-1)(n-2)(n-3) (n-2)(n-3)
20(20+1) 3(20-1)2
MK= [ ─────────── . 56,40] ─ [ ──────── ]
(20-1)(20-2)(20-3) (20-2)(20-3)
20.21 3(19)2
MK= [ ─────────── . 56,40 ] ─ [ ──────── ]
(19)(18)(17) (18)(17)
420 3.361
MK= [ ─────────── . 56,40 ] ─ [ ──────── ]
5814 (18)(17)
420 1083
MK= [ ─────────── . 56,40 ] ─ [ ──────── ]
5814 306
MK= 4,08 – 3,54 = 0,54, distribuição leptocurtica ou cume
170](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-170-320.jpg)

![n(n+1) 3(n-1)2
MK= [ ─────────── . M4 ] ─ [ ──────── ]
(n-1)(n-2)(n-3) (n-2)(n-3)
20(20+1) 3(20-1)2
MK= [ ─────────── . 52,22 ] ─ [ ──────── ]
(20-1)(20-2)(20-3) (20-2)(20-3)
20.21 3(19)2
MK= [ ─────────── . 52,22] ─ [ ──────── ]
(19)(18)(17) (18)(17)
420 3.361
MK= [ ─────────── . 52,22] ─ [ ──────── ]
5814 (18)(17)
420 1083
MK= [ ─────────── . 52,22] ─ [ ──────── ]
5814 306
MK= 3,77 – 3,54 = 0,23, distribuição leptocúrtica
172](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-172-320.jpg)
![Exemplo 2: Vamos calcular o Mk:
Declarações de Despesas feitas pelos Executivos de Uma Empresa
(Em 100 Reais)
Classes
Fi xi
──
[(x – Xi) / s ]4
──
[(x – Xi) / s ]4
Fi
00 |— 15 12 7,5 5,48 65,76
15 |— 30 23 22,5 0,49 11,27
30 |— 45 26 37,5 0,00 0,00
45 |— 60 18 52,5 0,09 1,62
60 |— 75 13 67,5 2,36 30,68
75 |— 90 8 82,5 13,91 111,28
Total 100 - - 220,61
Solução:
Ajustes análogos ao do momento de assimetria devem ser feitos no
momento de curtose:
Temos:
_
X = 40,65 e S = 21,67
n(n+1) 3(n-1)2
MK= [ ─────────── . M4 ] ─ [ ──────── ]
(n-1)(n-2)(n-3) (n-2)(n-3)
100(100+1) 3(100-1)2
MK= [ ─────────── . 220,61 ] ─ [ ──────── ] = -0,72
(100-1)(100-2)(100-3) (100-2)(100-3)
Distribuição platicúrtica ou plana.
173](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-173-320.jpg)



![Teste de Normalidade:
Na análise de dados, frequentemente iremos nos deparar com a
necessidade de realizar o teste de normalidade de variáveis quantitativas.
Existem vários testes de normalidade, mas um dos mais simples é o teste
chamado de Bera-Jarque. A fundamentação estatística utilizada como base
do teste de Bera-Jarque é dada pela equação:
(MAS)2
(Mk)2
BJ = n [ ──────── + ───────── ] < 6,0 para normalidade
6 24
Onde:
n= tamanho da amostra
Exemplo:
Do Exemplo 1, para o cálculo dos momentos de assimetria e
curtose, temos:
a)Cálculo de Bera-Jarques para Variável X:
(0)2
(0,54)2
BJ = 20 [ ──────── + ───────── ]
6 24
177](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-177-320.jpg)
![(0,54)2
BJ = 20 [ ───────── ] = 20 . 0,01 = 0,20 < 6,0, distribuição normal
24
Cálculo de Bera-Jarques para a Variável Y:
(0)2
(0,23)2
BJ = 20 [ ──────── + ───────── ]
6 24
(0,23)2
BJ = 20 [ ───────── ] = 20 . 0,00 = 0,00 < 6,0, distribuição normal
24
Conclusão:
Tanto a variável X quanto a variável Y tem distribuição normal.
178](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-178-320.jpg)



























































![Logo:
Anos Faturamento
(R$)
IP
1991= 100
Faturamento a Preços de 1991
(R$)
1991
1992
1993
1994
180.000
220.000
430.000
480.000
100,0
206,7
257,5
291,4
180.000
106.434
166.990
164.722
Pelo exame da tabela, vemos que o faturamento, no ano de 1994, foi,
em termos reais, inferior ao de 1991, embora, em termos nominais, tenha
aumentado.
Exemplo 2:
Uma categoria funcional está em negociação salarial com o empregador.
O salário atual da categoria é de R$2800,00. O empregador fez uma proposta
de reajuste salarial de 12,5% à categoria. O índice de preço do período é de
90%. A categoria deve aceitar a proposta do empregador?
Solução:
Salário Nominal com o aumento(SNA):
SNA= [2800 x 0,125] + 2800 = 350 + 2800 = R$ 3150,00
239](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-239-320.jpg)



![Logo,
100 x ( 1,35/1,50)
r= ———————— = (90/9) = 10%
9
Portanto, a taxa média aritmética de crescimento anual da básica
de juros no país X foi de 10%.
A taxa média de crescimento anual é de grande utilidade em
administração e economia, uma vez que possibilita fazer estimativas para
anos intermediários de cujos dados não dispomos(interpolação) ou
estimativas para anos futuros(extrapolação).
Exemplo:
Assim, se não dispuséssemos dos dados de 2003 da tabela do
exemplo 1, poderíamos obter sua estimativa por interpolação, utilizando a
taxa média que calculamos tendo encontrado 10%. Para o cálculo
teremos a seguinte fórmula derivada da anterior:
Px = P0 [1 + (r.n/ 100)]
Onde:
Px = população procurada
P0 = população inicial do período
r = taxa média de crescimento
n = lapso de tempo entre o ano inicial(P0) e o ano procurado(Px)
243](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-243-320.jpg)
![Portanto, sendo:
Px = população procurada
P0 = 1,50
r = 10%
n = 2003 – 2001 = 2
Logo:
Px = 1,50[ 1 + (10. 2/100)] = 1,80, exatamente o valor observado para este
dado em 2003 na tabela do exemplo 1.
Logo, a estimativa da taxa de juros básica no país X para 2003 é
de 1,80 %, segundo a taxa média de crescimento anual.
244](https://image.slidesharecdn.com/cursodeestatsticabsica-150607140745-lva1-app6892/85/Curso-de-estatistica-basica-244-320.jpg)


















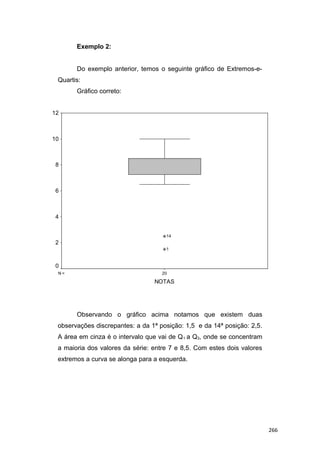

















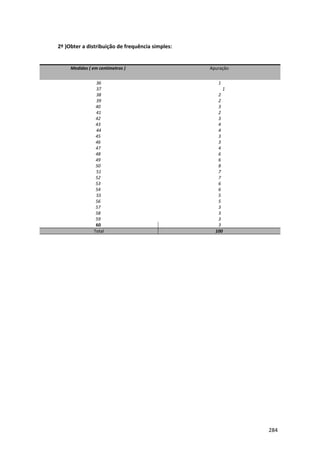







O documento descreve um livro sobre estatística básica. Apresenta agradecimentos, um prefácio descrevendo a experiência do autor e os objetivos do livro, e um sumário dos 10 capítulos que abordam conceitos básicos de estatística, variáveis, amostragem, método estatístico, séries estatísticas, números relativos, gráficos, distribuições de frequência, índices e análise exploratória de dados.