Baixado 243 vezes





![Big Data - Definição
O que é:
“Conjuntos de dados extremamente amplos e que, por este motivo, necessitam de
ferramentas especialmente preparadas para lidar com grandes volumes, de forma que
toda e qualquer informação nestes meios possa ser encontrada, analisada e
aproveitada em tempo hábil.” [ALECRIM, 2013]
“Transformação na forma como a informação é captada, processada e disseminada em
todos os níveis da sociedade.” [AVOYAN, 2013]
“Análise de grandes quantidades de dados para a geração de resultados importantes
que, em volumes menores, dificilmente seriam alcançados.” [ALECRIM, 2013]
5](https://image.slidesharecdn.com/apresentaobigdata-nosql-150730203802-lva1-app6892/85/Big-Data-e-NoSQL-5-320.jpg)











































![Referências
CRIVELINI, Wagner. Minhas primeiras impressões sobre o NoSQL. 2013. Disponível em: <http://imasters.com.br/banco-de-
dados/minhas-primeiras-impressoes-sobre-o-nosql/> Acesso em: 25 mar. 2015.
FINLLEY, Klint. A grande lista de casos para usar NoSQL. 2011. Disponível em: <http://imasters.com.br/artigo/21646/banco-de-
dados/a-grande-lista-de-casos-para-usar-nosql/> Acesso em: 25 mar. 2015.
FRANÇA, Guilherme. Entenda melhor o NoSQL e o Big Data. 2013. Disponível em: <http://blog.websolute.com.br/entenda-
melhor-o-nosql-e-o-big-data/> Acesso em: 25 mar. 2015.
GUIMARÃES, Saulo P. 30 casos que mostram o impacto do big data no seu dia a dia. 2014. Disponível em:
<http://exame.abril.com.br/tecnologia/noticias/30-casos-mostram-o-impacto-do-big-data-no-dia-a-dia> Acesso em: 25 mar. 2015.
HAMANN, Renan. Do bit ao Yottabyte: conheça os tamanhos dos arquivos digitais [infográfico]. 2011. Disponível em:
<http://www.tecmundo.com.br/infografico/10187-do-bit-ao-yottabyte-conheca-os-tamanhos-dos-arquivos-digitais-infografico-.htm>
Acesso em: 04 mai. 2015.
HARVEY, Cynthia . 50 Top Open Source Tools for Big Data. 2012. Disponível em: <http://www.datamation.com/data-center/50-
top-open-source-tools-for-big-data-1.html> Acesso em: 30 abr. 2015.
50](https://image.slidesharecdn.com/apresentaobigdata-nosql-150730203802-lva1-app6892/85/Big-Data-e-NoSQL-50-320.jpg)




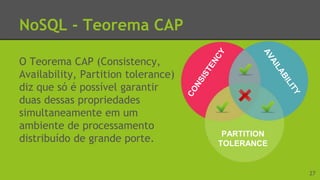
O documento apresenta os conceitos de Big Data e NoSQL. Define Big Data como a análise de grandes quantidades de dados estruturados e não estruturados para gerar novas informações. Apresenta os 5 Vs que caracterizam o Big Data (Volume, Variedade, Velocidade, Veracidade e Valor) e explica porque os bancos tradicionais não são adequados para lidar com Big Data. Resume também o que é NoSQL, apresentando alguns de seus tipos de armazenamento como alternativa aos bancos relacionais para lidar com a necessidade de escalabilidade



































































