Baixado 441 vezes























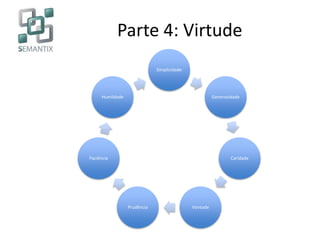
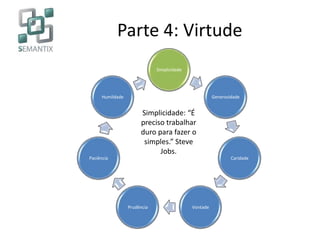
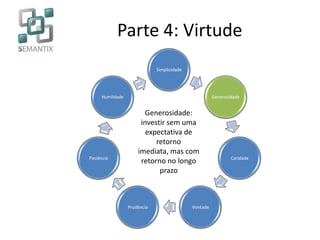
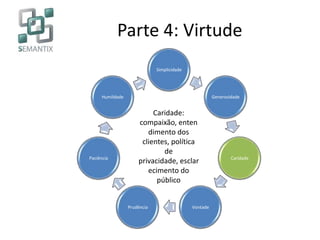






















O documento apresenta a Semantix, uma startup B2B especializada em big data, destacando suas soluções em busca, machine learning e processamento de linguagem natural. A empresa, com foco em serviços open source e consultoria, foi fundada em 2007 e se destaca pela implementação de tecnologias como Hadoop e Solr. O texto também discute a evolução do big data e suas aplicações em empresas renomadas como Google, Facebook e Netflix.















































