Baixado 13 vezes




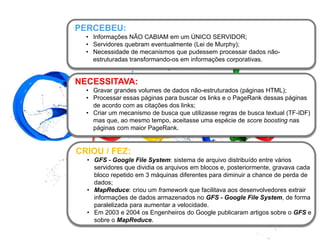







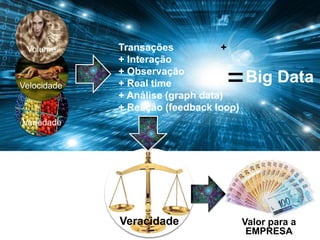

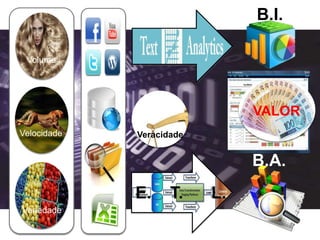


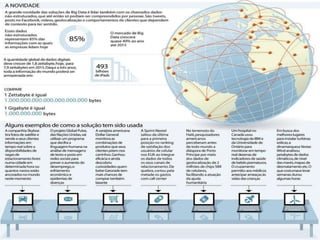




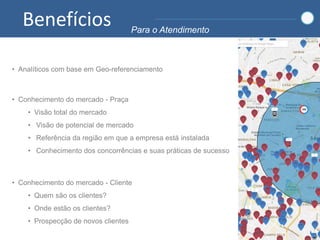
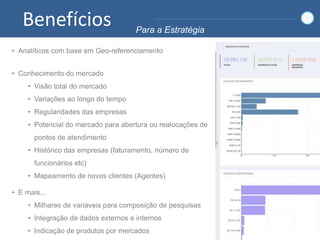

1) O documento discute como empresas como Google, Yahoo e LinkedIn usaram Big Data para resolver problemas de armazenamento e processamento de grandes volumes de dados não estruturados e criar novas soluções. 2) Também apresenta como empresas como Facebook, Amazon e Netflix usam Big Data para personalizar recomendações e melhorar a experiência do usuário. 3) Por fim, explica como o Sebrae pretende implementar soluções de Big Data para entender melhor seus mercados e clientes e aprimorar o atendimento.








































































