O documento apresenta Rodrigo Dornel e discute como o SQL Server pode interagir com dados não estruturados e sistemas de Big Data, incluindo XML, JSON, NoSQL, Hadoop, HDFS, MapReduce, Hive e PolyBase.
XML e JSON
Alterou alguns paradigmas de banco de
dados
Primeira experiência com dados não
estruturados
Introdução do tipo de dados XML
6.
XML e JSON
Introduzido na versão 2005.
Possibilita transformar linhas do banco de dados
em fragmentos de XML.
Permite carregar e armazenar dados XML
dentro SQL Server.
Usa a linguagem XQuery para manipular dados
dentro do XML, baseado em expressões XPath
(árvore do XML, navegação).
7.
XML e JSON
Propriedades ACID?
CHECK, Constraints?
Schema validation XSD
XQuery
8.
XML e JSON
Capaz de descrever diversos tipos de dados.
Seu propósito principal é a facilidade de
compartilhamento de informações através da
internet, serviços e afins.
9.
XML e JSON
Propriedades ACID?
CHECK, Constraints?
Indexação
Indexing JSON path using B-tree index
Indexing JSON array element using full-text
search index
10.
XML e JSON
Capaz de descrever diversos tipos de dados.
Seu propósito principal é a facilidade de
compartilhamento de informações através da
internet, serviços e afins.
XML e JSON
SQL Server 2016
JSON Auto, cria uma hierarquia automaticamente
JSON Path, você especifica as hierarquias
ISJSON(), valida se a coluna está no padrão JSON
JSON_QUERY() “SUB CONSULTA”
JSON_VALUE(), retorna o valor do nó
JSON_MODIFY(), altera valores
OPENJSON(), carrega um campo “texto”
convertendo ele para JSON. OPENJSON é uma
função (TVF), imagina um CAST ou CONVERT.
INCLUDE_NULL_VALUES
SQL vs NoSQL
SQL, fortemente ligado ao mundo relacional,
consultas bem definidas, esquemas rígidos e
ACID.
NoSQL, termo genérico para uma classe
definida de banco de dados não-relacionais.
Não apresenta estrutura rígida, alguns
chamam de livre de esquema, pouco ou
nenhum controle ACID.
15.
Hadoop
Plataforma feitaem Java para processamento
distribuído de grandes massas de dados.
Basicamente composto pelo HDFS, Yarn e
MapReduce.
Projeto é mantido pela fundação Apache.
Para nós o mais familiar ou conhecido é o
HDInsight feito pela Hortomworks para a
Microsoft.
Azure ou Local (só um nó)
16.
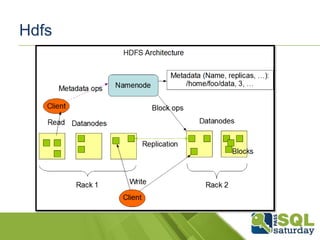
Hdfs
Sistemas dearquivos feito para rodar em
hardware básico.
Feito para trabalhar com grandes
quantidades de dados.
Tolerante a falha.
Não leva em consideração aspectos
tradicionais de acesso a dados e sim um
estilo de acesso como um streaming de
dados.
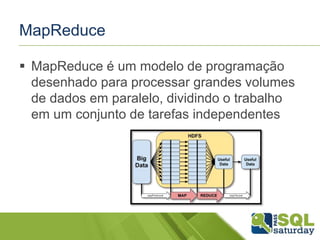
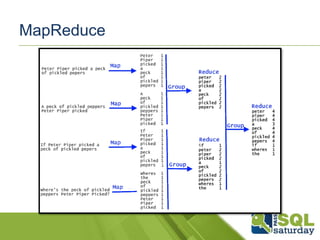
MapReduce
MapReduce éum modelo de programação
desenhado para processar grandes volumes
de dados em paralelo, dividindo o trabalho
em um conjunto de tarefas independentes
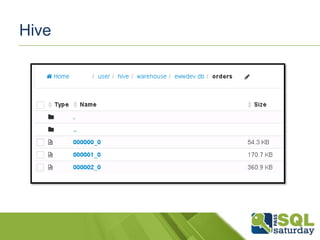
Hive
Basicamente umainfraestrutura de
datawarehouse para rodar no topo da
arquitetura do Hadoop para oferecer
sumarização dos dados, consultas e análise.
Ele oferece uma linguagem SQL-like
chamada de HiveQL com leitura e esquemas
que permitem que consultemos os dados
MapReduce como se consultássemos banco
tradicionais.
22.
Hive
Usa tabelassimilares ao modelo relacional.
Particionadas, overwriting e appending data.
Cada tabela é um diretório no HDFS, pode
ser dividida em partições ou buckets.
Hive
Suporta amaioria dos tipos de dados
primitivos.
BIGINT, BINARY, BOOLEAN, CHAR,
DECIMAL, DOUBLE, FLOAT, INT,
SMALLINT, STRING, TIMESTAMP, and
TINYINT.
Adicional de dados complexos como structs,
maps and arrays
25.
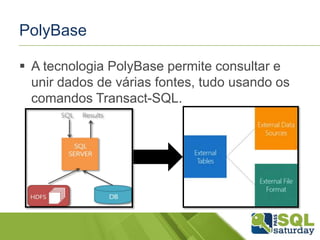
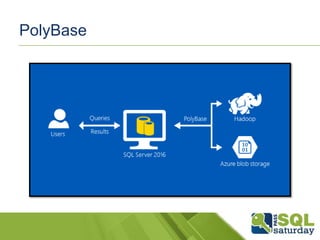
PolyBase
A tecnologiaPolyBase permite consultar e
unir dados de várias fontes, tudo usando os
comandos Transact-SQL.
PolyBase
Fonte dedados Externa, Hadoop, Azure Blob.
Definição de como os dados estão organizados, ou
seja, separadores de colunas.
Um esquema que represente esses dados, colunas,
tipos de dados e localização desse arquivo dentro
do seu sistema de arquivos.
Necessário ter o Java JDK antes de instalar e/ou
pode ser interessante instalar um drive ODBC para
Hive.
28.
PolyBase
Push computationto Hadoop.
Scale compute resources.
Catalog Views
SELECT * FROM sys.external_data_sources;
SELECT * FROM sys.external_file_formats;
SELECT * FROM sys.external_tables;
#3 Falem que o evento é gratuito pra todos, e que os patrocinadores são os responsáveis por garantir o coffee e a infra-estrutura basica pro evento acontecer. Em contra partida, eles querem mostrar seus produtos e serviços, é legal aos participantes conhecerem o que eles tem a oferecer e aceitar receber contatos deles via email.
































































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)






























