O documento apresenta a aplicação da técnica MapReduce na modelagem de algoritmos genéticos para resolver o Problema do Caixeiro Viajante, utilizando a tecnologia Apache Hadoop. A pesquisa evidencia que a técnica MapReduce é eficiente no processamento de grandes volumes de dados, proporcionando melhores soluções em otimização. O trabalho inclui uma nova modelagem do algoritmo genético, visando melhorar o desempenho e simplificar o desenvolvimento da solução proposta.

















![16
Para ser preciso, MapReduce pode referir-se a três conceitos distintos, mas
relacionados. Primeiro, MapReduce é um modelo de programação. Segundo,
MapReduce pode referir-se ao framework de execução, que coordena a execução
de programas escritos neste estilo particular de tecnologia. Finalmente, MapReduce
pode se referir à implementação de software do modelo de programação e do
framework de execução, como é o caso das várias implementação existentes, como
a ferramenta proprietária do Google, e a solução em código aberto do Hadoop, para
processadores multicore (Phoenix) e etc. (LIN & DYER, 2010, p. 21).
2.2 MAPREDUCE
Como visto, MapReduce é um modelo de programação especificado em
funções map e reduce. Pares de chave/valor formam a estrutura básica de dados
em MapReduce. Parte do projeto de algoritmos MapReduce envolve impor a
estrutura de chave/valor em conjuntos de dados com qualquer tipo de dado (inteiro,
texto, etc). Em alguns algoritmos, as chaves de entrada não são particularmente
significativas e são simplesmente ignoradas durante o processamento, enquanto em
outros casos chaves de entrada são usados para identificar exclusivamente um dado
(LIN & DYER, 2010, p. 22).
Em MapReduce, o programador define a função map e a função reduce com
as seguintes assinaturas (onde [ e ] representam uma lista de valores) :
map: (k1, v1) [(k2, v2)]
reduce: (k2, [v2]) [(k3, v3)]
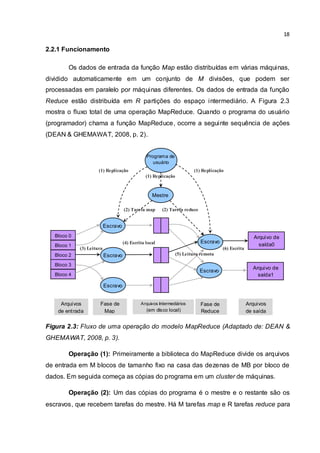
A entrada para um trabalho MapReduce começa com os dados
armazenados no sistema de arquivos distribuído. Como podemos ver na Figura 2.2,
os algoritmos devem levar um conjunto de pares chave/valor de entrada e produzir
um conjunto de pares chave/valor de saída. O usuário (programador) da biblioteca
MapReduce modela o algoritmo como duas funções Map e Reduce. O Map escrito
pelo programador leva um par de entradas e produz um conjunto de pares
chave/valor intermediários. Posteriormente, são unidos todos os valores](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-17-320.jpg)
![17
intermediários associados com a mesma chave e passa o resultado para a função
Reduce. A função Reduce, também escrita pelo programador, aceita uma chave
intermediária e seu conjunto de valores. A função Reduce mescla esses valores
para formar um conjunto possivelmente menor de valores (DEAN & GHEMAWAT,
2008, p. 1). Os dados intermediários chegam a cada redutor em ordem, classificadas
pela chave, no entanto, nenhuma relação de ordenação é garantida para chaves
através de diferentes redutores. Pares chave/valor de saída de cada redutor são
escritos persistentemente no sistema de arquivos distribuído enquanto que pares de
chave/valor intermediários são transitórios e não preservados. A saída termina em
vários arquivos no sistema de arquivos distribuído, em que corresponde ao número
de redutores (LIN & DYER, 2010, p. 22).
Figura 2.2: Vista simplificada do funcionamento de um trabalho MapReduce
(Adaptado de: LIN & DYER, 2010, p. 23).
K1 V1 K1 V1 K1 V1 K1 V1
reducer reducer reducer
K2 V2 K2 V2 K2 V2 K2 V2
K3 V3
Shuffle e Sort: Agregação de Valores por Chaves
K2 [V2] K2 [V2] K2 [V2]
mapper mapper mapper mapper
K3 V3 K3 V3](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-18-320.jpg)





























![49
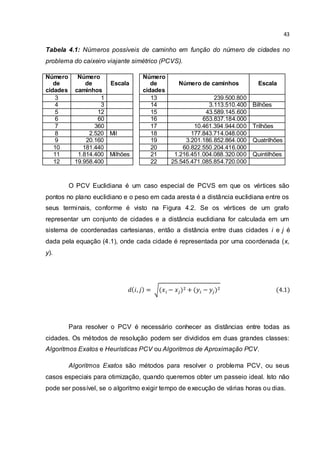
Figura 4.7: Funcionamento do operador OX.
Este cruzamento é mais adequado quando é usado com a representação de
Sequência Ordenada, pois preserva mais as estruturas ordenadas dos
cromossomos dos pais, promovendo assim a herança genética.
Além desses, existem outros operadores que se aplicam ao problema do
caixeiro viajante, como o operador Matrix Crossover (MX), um operador que usar a
representação matricial, e o Modified Order Crossover (MOX), que é semelhante ao
operador OX, mas com apenas um ponto de corte (BRYANT, 2000, p. 15-16).
4.2.4 Operadores de mutação
Há vários operadores de mutação apropriados para problemas de
permutações de valores, até operadores de mutação heurística apropriados para o
problema do caixeiro viajante.
Alguns operadores de mutação que podem ser usados são: por inserção,
deslocamento, intercâmbio recíproco e por inversão. A mutação por inserção é
quando há uma seleção aleatória de uma cidade e sua inserção em uma posição
aleatória. A mutação por deslocamento é quando selecionamos um subcaminho e
insere-o em uma posição aleatória. Temos também intercâmbio recíproco onde há
uma escolha de duas cidades aleatórias e há uma troca de posição. O operador de
inversão é uma forma diferente de mutação, que consiste na escolha aleatória de
Pai 1 ABC | DEF | GHIJ
Pai 2 GHI | JAB | EFCD
1º 2 º
XXX | DEF | XXXX
[EF]C[D]GHIJAB CGHIJAB
JABDEFCGHI
Filho 1:
XXX | JAB | XXXX
GHI[JAB]CDEF GHICDEF
DEFJABGHIC
Filho 2:](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-50-320.jpg)








![60
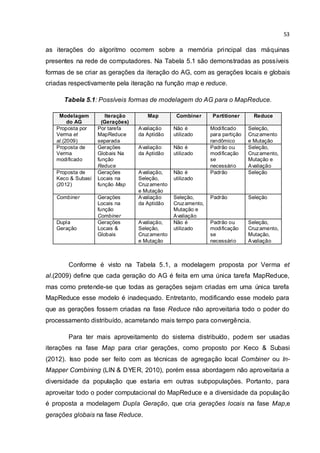
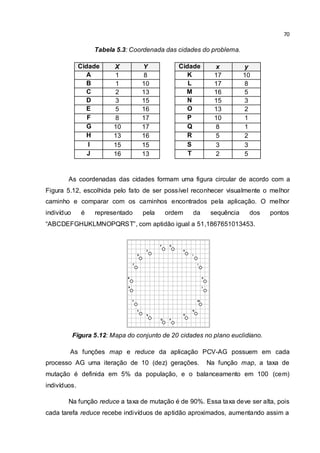
Os dados do arquivo de entrada formam pares chave/valor: a chave é o
número da linha (que não é tratado no arquivo), e o valor é própria linha que
representa o indivíduo. A função map avalia e armazena uma quantidade de linhas
(indivíduos) em uma lista, formando a população inicial para o processo AG gerar
novos indivíduos, esses são emitidos na forma do par aptidão/indivíduo
(chave/valor), sendo que a chave é o arredondamento da aptidão para um número
inteiro e o valor é um par <cromossomo/aptidão>10
. No final de cada emissão há um
retorno da coleta de dados de entrada, se ainda houver dados de entrada, o
processo AG da função map se repete, emitindo novos pares aptidão/indivíduo como
no exemplo:
( 53, <ABCDEFGHIJ, 53.3475288096413>)
( 51, <GHIJABEFCD, 50,6532924781218>)
( 53, <EBFHGIJACD, 52.8074130652778>)
( 51, <EBHFCDIJGA, 51.4288322764095>)
A saída da função map é processada pela fase intermediária (Shuffle e Sort),
agrupando os pares aptidão/indivíduo (chave/valor) pela aptidão, porém essa forma
gera o risco de executar várias funções reduce com um só indivíduo, tornando inútil
o processo AG; isso é evitado se a chave do par aptidão/indivíduo for uma
aproximação da aptidão. Após a fase intermediária os dados são enviados para a
fase reduce da seguinte forma:
(51, [<GHIJABEFCD, 50,6532924781218>, <EBHFCDIJGA, 51.4288322764095>])
(53, [<ABCDEFGHIJ, 53.3475288096413>, <EBFHGIJACD, 52.8074130652778>])
Para cada chave há uma lista de indivíduos, que é usada pela função reduce
para gerar uma nova população através do processo AG. Na função reduce a chave
não é utilizada e a lista é usada como população inicial. No final da tarefa é emitido o
melhor indivíduo de cada função reduce através do par aptidão/indivíduo, como
desta forma:
(27.866056254812328, ACEHIBJFDG)
(28.014106081769356, GFJBHIECAD)
Todo esse processo de fluxo de dados pode ser visto na Figura 5.4.
10
Na modelagem MapReduce o par <cromossomo/aptidão> e o cromossomo (caminho) tem a mesma
denominação “Indivíduo”.](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-61-320.jpg)
![61
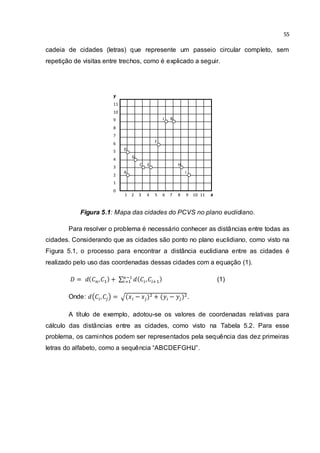
Figura 5.4: Fluxo lógico de dados do processo MapReduce para o AG.
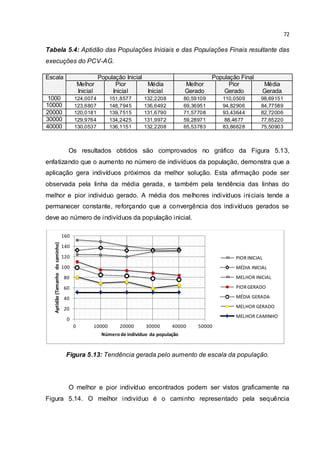
Na essência do processo, as funções map e reduce mantém o controle dos
melhores indivíduos, no qual são sempre enviados pelo fluxo de dados. Isso resulta
na saída dos melhores indivíduos encontrados para o PCV. No término do processo
é realizada a gravação das saídas da fase reduce em um arquivo no sistema de
arquivos do Hadoop (o HDFS).
5.4 IMPLEMENTAÇÃO
Com base na estrutura de funcionamento do algoritmo genético PCV, esta
seção apresenta a implementação da aplicação denominado PCV-AG, no contexto
da tecnologia MapReduce do Hadoop. Para facilitar o entendimento da solução, as
funções principais de mapeamento e redução estão codificadas em forma de
algoritmos; as listagens em código Java encontram-se na seção de anexos.
5.4.1 Algoritmo
A função map é implementada pela classe MAPPER, descrito no algoritmo
da Figura 5.5. Nessa classe há três métodos:
1) MAP: trata e processa os valores de entrada para criar novos indivíduos,
inserindo cada um em uma nova população (grupo da subpopulação), que tem o
tamanho gerenciado por um controle de balanceamento, esse controle chama o
método GERACAOLOCAL quando a população atingir um determinado tamanho.
Entrada | map |
| shuffle
reduce > Saída
ABCDEIGHFJ
GIJABEFCDH
BEFGHIJACD
EBGFHCDIJA
( 0, ABCDEIGHFJ)
( 1, GIJAB EFCDH)
( 2, BEFGHIJACD)
( 3, EBGFHCDIJA)
( 53, < ABCDEFGHIJ, 53.3475288096413>)
( 51, <GHIJABEFCD, 50,6532924781218>)
( 53, <EBFHGIJACD, 52.8074130652778>)
( 51, <EBHFCDIJGA, 51.4288322764095>)
(51, [<GHIJABEFCD, 50,6532924781218>, <EBHFCDIJGA, 51.4288322764095>])
(53, [<ABCDEFGHIJ, 53.3475288096413>, <EBFHGIJACD, 52.8074130652778>])
(27.866056254812328, ACEHIBJFDG)
(28.014106081769356, GFJBHIECAD)
27.866056254812328, ACEHIBJFDG
28.014106081769356, GFJBHIEC AD](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-62-320.jpg)

![63
Emite permite gerar os dados (a variável Aptidão e o Indivíduo) para fase
intermediária.
1: classe MAPPER
2: atributo População novo objeto lista [Indivíduo ]
3: atributo OperaçãoGenética novo objeto OperaçãoGenética
4: método MAP (chave, valor)
5: Indivíduo novo objeto Indivíduo
6: Indivíduo.Cromossomo valor
7: Indivíduo.Aptidão OperaçãoGenética.CalcularAptidão(Indivíduo)
8: População.Adicionar(Indivíduo)
9: OperaçãoGenética.TaxaMutação(BaixaTaxa)
10: se (População.Tamanho() = ValorDeBalanceamento)
11: GeracaoLocal ()
12: método GERACAOLOCAL ()
13: variável CondiçãoDeParada NúmeroMáximoDeGerações
14: variável Geração 0
15: enquanto (Geração < CondiçãoDeParada)
16: População OperaçãoGenética.Seleção(População)
17: População OperaçãoGenética.Cruzamento(População)
18: População OperaçãoGenética.Mutação(População)
19: População OperaçãoGenética.CalcularAptidão(População)
20: Geração Geração + 1
21: fimEnquanto
22: População.Adicionar(OperaçãoGenética.MelhorIndivíduo())
23: para todo Indivíduo em População faça
24: variável Aptidão Arredondar(Indivíduo. Aptidão)
25: Emite (Chave Aptidão, Valor Indivíduo)
26: fimParaTodo
27: População.Limpar()
28: método CLEANUP ()
29: GeraçãoLocal ()
Figura 5.5: Código Map do Algoritmo Genético MapReduce.
A função reduce é implementada pela classe REDUCER, descrita no
algoritmo da Figura 5.6. Essa classe tem o método REDUCE, responsável por criar a
iteração que executa o processo AG, que manipula uma subpopulação de indivíduos
de entrada, que é processada para gerar novos indivíduos. No final, o melhor
indivíduo encontrado na subpopulação é emitido para a saída da função.](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-64-320.jpg)
![64
1: classe REDUCER
2: atributo População novo objeto lista [Indivíduo ]
3: atributo OperaçãoGenética
4: método REDUCE (Chave Aptidão, Valor [Indivíduo ] )
5: População Valor
6: OperaçãoGenética novo objeto OperaçãoGenética
7: OperaçãoGenética.TaxaMutação(AltaTaxa)
8: variável CondiçãoDeParada NúmeroMáximoDeGerações
9: variável Geração 0
10: enquanto (Geração < CondiçãoDeParada)
11: População OperaçãoGenética.Seleção(População)
12: População OperaçãoGenética.Cruzamento(População)
13: População OperaçãoGenética.Mutação(População)
14: População OperaçãoGenética.CalcularAptidão(População)
15: Geração Geração + 1
16: fimEnquanto
17: Indivíduo OperaçãoGenética.MelhorIndivíduo()
18: variável Cromossomo Indivíduo.Cromossomo
19: variável Aptidão Indivíduo.Aptidão
20: Emite (Chave Aptidão, Valor Cromossomo)
21: População.Limpar()
Figura 5.6: Código Reduce do Algoritmo Genético MapReduce.
A técnica MapReduce define que os dados do fluxo de dados podem ser de
qualquer tipo. Isso permite que os indivíduos (presentes no fluxo de dados) do
modelo Dupla Geração, sejam definidos como um par cromossomo/aptidão. Dessa
forma, os indivíduos podem ser definidos por uma classe em uma instância que é
vista na linha 5 do algoritmo da Figura 5.5. Tais objetos (indivíduos) são os principais
dados da tarefa MapReduce para a aplicação PCV-AG.
As operações do Algoritmo Genético estão fracamente acoplados ao
algoritmo do MapReduce, isso permite abstraí-los da implementação apresentada na
tecnologia MapReduce, concentrando-os separadamente em uma só classe
denominada “OperaçãoGenética”, como pode-se observar na linhas 16-19 da Figura
5.5, e 11-14 da Figura 5.6, especificamente onde ocorre o processo AG. Assim,
torna o algoritmo Map e Reduce mais simples e flexível para ser adaptado a outros
contextos de problema que sigam o paradigma do Caixeiro Viajante.](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-65-320.jpg)



![68
OperaçãoGenética tem os métodos principais, calcularAptidão(), seleção(),
cruzamento(), mutação() e os auxiliares setTaxaMutação() e getMelhorIndivíduo().
Figura 5.11: Código simplificado da classe OperacaoGenetica.
Os métodos calcularAptidão, seleção, cruzamento e mutação, recebem uma
população de indivíduos para efetuar sua operação genética, e no final retornam a
população processada. O método setTaxaMutação() define a porcentagem usada
pelo método mutação(); essa taxa é diferente para as funções map e reduce. O
método getMelhorIndivíduo() retorna o melhor indivíduo armazenado no atributo
melhorIndivíduo.
Finalmente, a classe CaixeiroViajante é a classe que executa o trabalho
MapReduce. Para isso, a partir do método estático main(), há o controle da
execução do trabalho, a definição da entrada e saída do caminho do arquivo ou
diretório dos dados, a especificação de quais classes fazem parte da função map e
reduce, e o controle dos tipos de entrada e saída das funções map e reduce. No
final, o método monitora o progresso do trabalho MapReduce.
public class OperacaoGenetica {
private Individuo melhorIndividuo = new Individuo();
private int tamanhoIndividuo = 10;
private double taxaMutacao = 5/100;
private String alfabeto = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
private int[][] distancias = {{ 1, 2 }, { 7, 9 }, { 3, 3 }, { 1, 5 }, {
4, 3 }, { 5, 6 }, { 2, 4 }, { 8, 3 }, { 9, 2 }, { 6, 9 }};
public ArrayList<Individuo> calcularAptidao(ArrayList<Individuo>
populacao)
public ArrayList<Individuo> selecao( ArrayList<Individuo> populacao)
public ArrayList<Individuo> cruzamento(ArrayList<Individuo> populacao)
public ArrayList<Individuo> mutacao(ArrayList<Individuo> populacao)
public Individuo getMelhorIndividuo()
public void setTaxaMutacao(double taxa)
}](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-69-320.jpg)













![84
ANEXO A
Implementação da classe Individuo.
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Individuo implements Writable {
private String cromossomo;
private double aptidao;
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(cromossomo);
out.writeDouble(aptidao);
}
@Override
public void readFields(DataInput in) throws IOException {
this.cromossomo = in.readUTF();
this.aptidao = in.readDouble();
}
@Override
public String toString() {
return cromossomo + "t" + aptidao;
}
public String getCromossomo() {
return this.cromossomo;
}
public void setCromossomo(String individuo) {
this.cromossomo = individuo;
}
public double getAptidao() {
return aptidao;
}
public void setAptidao(double aptidao) {
this.aptidao = aptidao;
}
public String[] getIndArray() {
String[] individuo = new String[this.cromossomo.length()];
for (int i = 0; i < this.cromossomo.length(); i++) {
individuo[i] = ""+this.cromossomo.charAt(i);
}
return individuo;
}
public void setIndArray(String[] individuo) {
this.cromossomo = "";
for (String i: individuo) {
if(i != null){
this.cromossomo += i;
}
}
}
}](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-85-320.jpg)

![86
Implementação da classe CaixeiroViajanteReducer .
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class CaixeiroViajanteReducer extends
Reducer<IntWritable, Individuo, DoubleWritable, Text> {
private ArrayList<Individuo> populacao = new ArrayList<Individuo>();
private OperacaoGenetica operacaoGenetica;
@Override
public void reduce(IntWritable key, Iterable<Individuo> values,
Context context) throws IOException, InterruptedException {
operacaoGenetica = new OperacaoGenetica();
operacaoGenetica.setTaxaMutacao(0.9);
for (Individuo val : values) {populacao.add(val); }
if(populacao.size() == 1) {
operacaoGenetica.setMelhorIndividuo(populacao.get(0));
}
int CondicaoDeParada = 10;
int geracao = 0;
while (geracao < CondicaoDeParada) {
populacao = operacaoGenetica.selecao(populacao);
populacao = operacaoGenetica.cruzamento(populacao);
populacao = operacaoGenetica.mutacao(populacao);
populacao = operacaoGenetica.calcularAptidao(populacao);
geracao++;
}
Individuo ind = operacaoGenetica.getMelhorIndividuo();
context.write(new DoubleWritable(ind.getAptidao()), new
Text(ind.getCromossomo()));
populacao.clear();
}
}
Implementação da classe CaixeiroViajante .
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CaixeiroViajante {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
args = new String[2];
args[0] = System.getProperty("user.dir") + "/Input";
args[1] = System.getProperty("user.dir") + "/Output";
}
Job job = new Job();
job.setJarByClass(CaixeiroViajante.class);
job.setJobName("Problema do Caixeiro Viajante");](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-87-320.jpg)
![87
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(CaixeiroViajanteMapper.class);
job.setReducerClass(CaixeiroViajanteReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Individuo.class);
job.setOutputKeyClass(DoubleWritable.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Implementação da classe OperacaoGenetica.
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
public class OperacaoGenetica {
private Individuo melhorIndividuo = new Individuo();
private int tamanhoIndividuo = 20;
private double taxaMutacao = 5/100;
private String alfabeto = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
private int[][] distancias = {
{ 1, 8 }, { 1,10 }, { 2,13 }, { 3,15 }, { 5,16 },
{ 8,17 }, { 10,17}, { 13,16}, { 15,15}, { 16,13},
{ 17,10}, { 17,8 }, { 16,5 }, { 15,3 }, { 13,2 },
{ 10,1 }, { 8, 1 }, { 5, 2 }, { 3, 3 }, { 2, 5 } };
public ArrayList<Individuo> calcularAptidao(ArrayList<Individuo> populacao)
throws IOException {
ArrayList<Individuo> popula = new ArrayList<Individuo>();
double aptidao =0;
int x1, x2, y1, y2, pos;
String[] indString;
for (Individuo indi : populacao) {
indString = new String[tamanhoIndividuo];
indString = indi.getIndArray();
for (int j = 0; j < tamanhoIndividuo; j++) {
pos = alfabeto.indexOf(indString[j]);
x1 = distancias[pos][0];
y1 = distancias[pos][1];
pos=alfabeto.indexOf(indString[(j+1)%tamanhoIndividuo]);
x2 = distancias[pos][0];
y2 = distancias[pos][1];
aptidao+=Math.sqrt(Math.pow(x1-x2,2)+Math.pow(y1-y2,2));
}
indi.setAptidao(aptidao);
setMelhorIndividuo(indi);
popula.add(indi);
aptidao = 0;
}
return popula;
}
public ArrayList<Individuo> selecao( ArrayList<Individuo> populacao) throws
IOException {
int tamanhoPop = populacao.size();
Individuo[] popula = new Individuo[tamanhoPop];
popula = populacao.toArray(popula);](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-88-320.jpg)
![88
popula = QuickSort(popula, 0, tamanhoPop - 1);
populacao.clear();
for(int i=0;i<(popula.length*(1-0.3));i++){populacao.add(popula[i]);}
for(int i=0; i<(popula.length*0.3); i++){populacao.add(popula[i]);}
return populacao;
}
private Individuo[] QuickSort(Individuo[] pop, int inicio, int fim) {
int meio;
if (inicio < fim) {
int topo, indice;
Individuo pivo;
pivo = pop[inicio];
topo = inicio;
for (indice = inicio + 1; indice <= fim; indice++) {
if (pop[indice].getAptidao() < pivo.getAptidao()) {
pop[topo] = pop[indice];
pop[indice] = pop[topo + 1];
topo++;
}
}
pop[topo] = pivo;
meio = topo;
QuickSort(pop, inicio, meio);
QuickSort(pop, meio + 1, fim);
}
return pop;
}
public ArrayList<Individuo> cruzamento(ArrayList<Individuo> populacaoA)
throws IOException {
int tamanhoPop = populacaoA.size();
Individuo[] populacao = new Individuo[tamanhoPop];
populacao = populacaoA.toArray(populacao);
populacaoA.clear();
String[] indPai1,indPai2, indFilho1, indFilho2;
int pp = 3, sp = 7, k, c1, c2;
int tamanhoSecao = (int) tamanhoIndividuo/2;
Random r = new Random();
boolean presente;
for (int i = 0; i < tamanhoPop; i += 2) {
indFilho1 = new String[tamanhoIndividuo];
indFilho2 = new String[tamanhoIndividuo];
pp = r.nextInt(tamanhoSecao - 1);
sp = pp+tamanhoSecao;
if (i + 1 < tamanhoPop) {
indPai1 = populacao[i].getIndArray();
indPai2 = populacao[i + 1].getIndArray();
for (int c = pp; c <= sp; c++) {
indFilho1[c] = indPai1[c];
indFilho2[c] = indPai2[c];
}
c1 = sp + 1;
c2 = sp + 1;
for (int j=sp+1; j!=pp; j=(j + 1)%tamanhoIndividuo) {
do {
presente = false;
for (k = pp; k <= sp; k++) {
presente |= indPai2[c2].equals(indFilho1[k]);}
if (!presente) {indFilho1[j] = indPai2[c2];}
c2 = (c2 + 1) % tamanhoIndividuo;](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-89-320.jpg)
![89
} while (presente);
do {
presente = false;
for (k = pp; k <= sp; k++) {
presente |= indPai1[c1].equals(indFilho2[k]);}
if (!presente) {indFilho2[j] = indPai1[c1];}
c1 = (c1 + 1) % tamanhoIndividuo;
} while (presente);
}
Individuo indF1 = new Individuo();
Individuo indF2 = new Individuo();
indF1.setIndArray(indFilho1);
indF2.setIndArray(indFilho2);
populacaoA.add(indF1);
populacaoA.add(indF2);
} else {
populacaoA.add(populacao[i]);
}
}
return populacaoA;
}
public ArrayList<Individuo> mutacao(ArrayList<Individuo> populacao) throws
IOException {
int tamanhoPop = populacao.size();
String cidade;
String[] indString;
Individuo indi;
Random indRandom = new Random();
int ri, rc1, rc2;
if(tamanhoPop == 1){taxaMutacao = 1;}
for (int i = 0; i < tamanhoPop * taxaMutacao; i++) {
ri = indRandom.nextInt(tamanhoPop);
indi = populacao.get(ri);
indString = indi.getIndArray();
rc1 = indRandom.nextInt(tamanhoIndividuo);
rc2 = indRandom.nextInt(tamanhoIndividuo);
cidade = indString[rc1];
indString[rc1] = indString[rc2];
indString[rc2] = cidade;
indi.setIndArray(indString);
populacao.set(ri, indi);
}
return populacao;
}
public Individuo getMelhorIndividuo() {return melhorIndividuo;}
public void setMelhorIndividuo(Individuo ind) {
if (getMelhorIndividuo().getAptidao() == 0
|| getMelhorIndividuo().getAptidao()
> ind.getAptidao()){
Individuo MelhorInd = new Individuo();
MelhorInd.setCromossomo(ind.getCromossomo());
MelhorInd.setAptidao(ind.getAptidao());
this.melhorIndividuo = MelhorInd;
}
}
public double getTaxaMutacao(){return this.taxaMutacao;}
public void setTaxaMutacao(double taxa){this.taxaMutacao = taxa; }
}](https://image.slidesharecdn.com/tacfinal-2-150504191731-conversion-gate01/85/Aplicacao-da-Tecnica-Mapreduce-na-Modelagem-de-Algoritmos-Geneticos-para-o-Problema-do-Caixeiro-Viajante-90-320.jpg)



























