Transferir como PDF, PPTX










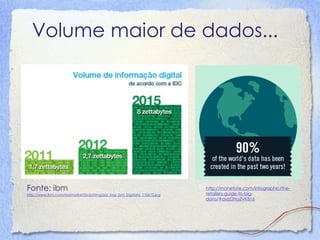



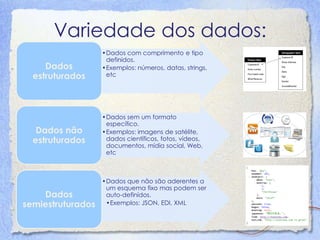
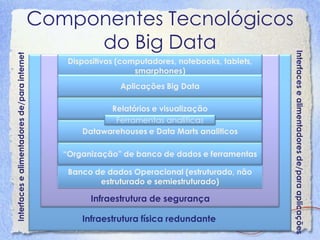





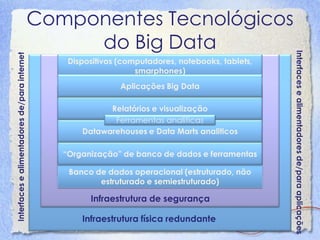










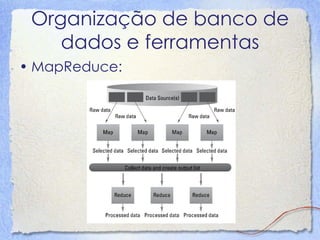







O documento discute Big Data, definindo-o como dados que possuem alto volume, velocidade e variedade. Detalha como a mídia tem relatado sobre Big Data e explica os 3Vs (Volume, Velocidade e Variedade). Também descreve os principais componentes tecnológicos de Big Data, incluindo bancos de dados, MapReduce, Hadoop e mineração de dados.















































