O trabalho de conclusão de curso de Roger Pauer Rocha Viana explora o uso de data mining como uma técnica de business intelligence, destacando sua importância na análise de grandes volumes de dados e na tomada de decisões estratégicas nas empresas. O estudo aborda o processo de descoberta de conhecimento em bases de dados e os algoritmos envolvidos, enfatizando os benefícios que as empresas podem obter ao implementar essas técnicas. A pesquisa visa não apenas atualizar o conhecimento sobre o tema, mas também demonstrar como a inteligência competitiva pode ser potencializada por meio da aplicação do data mining.





































![39
Após a escolha do atributo, é criado e desenhado o nó e as suas ramificações de
acordo com todos os valores possíveis para o atributo. A criação das ramificações gera novos
nós que devem verificados em seguida.
2.3.7 Métodos baseados em Lógica Nebulosa
Para Goldschmidt e Passos (2005, p. 183), a Lógica Nebulosa objetiva modelar o
modo aproximado de raciocínio humano, buscando criar sistemas computacionais capazes de
tomar decisões racionais em um ambiente incerto e impreciso. A Lógica Nebulosa
disponibiliza um mecanismo de manipulação das informações imprecisas, como os conceitos
de pequeno, alto, muito, pouco, bom, ruim, quente, frio, etc, fornecendo assim uma resposta
próxima a uma questão baseada em conhecimentos não exatos, incompletos ou parcialmente
confiáveis.
Diversos métodos de data mining foram adaptados de forma a incorporar a
flexibilidade proporcionada pela Lógica Nebulosa, sendo um deles o algorítmo de Wang-
Mendel, concebido para aplicação na tarefa de previsão de series temporais.
Segundo Goldschmidt e Passos (2005, p. 113), “O método Wang-Mendel consiste
em abstrair regras nebulosas a partir de conjuntos de dados históricos, utilizamos esses dados
para definir os antecedentes de os consequentes das regras nebulosas”.
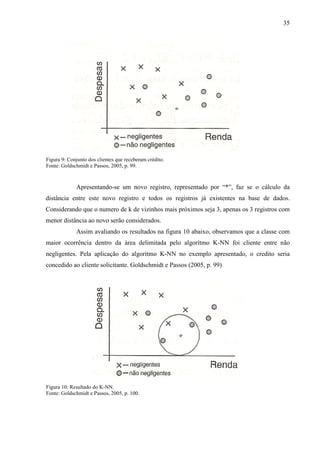
Temos que considerar então X(k), K=1,2,... uma série temporal, em que X(k)[U-
;U+
] em m conjuntos nebulosos de comprimento igual, devendo m ser um valor impar.
Pode ser visto na figura 12 abaixo a ilustração de uma serie temporal sendo
dividida em 7 conjuntos nebulosos.](https://image.slidesharecdn.com/monografiarogerpauerformatada-final-130629064313-phpapp01/85/Data-mining-Auxiliando-as-empresas-na-tomada-de-decisao-39-320.jpg)