Transferir como PDF, PPTX













![© 2018, Ambiente Livre. Todos direitos reservados. www.ambientelivre.com.br +55 (41) 3308-34386
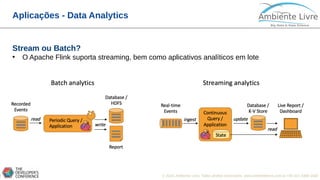
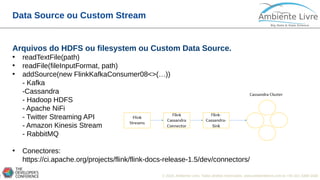
DataStream Transformations
Transformation
• Map - dataStream.map { x => x * 2 }
• FlatMap - dataStream.flatMap { str => str.split(" ") }
• Filter - dataStream.filter { _ != 0 }
• KeyBy - dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a Tuple
• Reduce - keyedStream.reduce { _ + _ }
• Fold - val result: DataStream[String] =
keyedStream.fold("start")((str, i) => { str + "-" + i })
• Aggregations - keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")](https://image.slidesharecdn.com/apacheflinkaquartageracaodobigdatav4-180719141955/85/Apache-Flink-a-Quarta-Geracao-do-Big-Data-26-320.jpg)

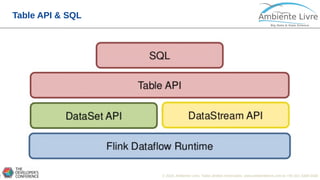



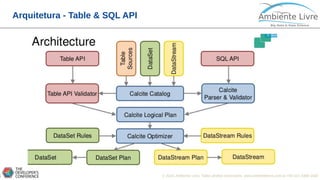
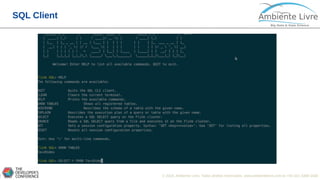
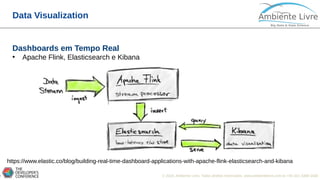





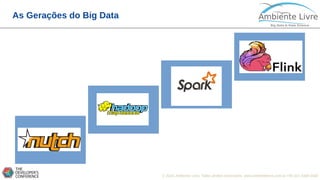
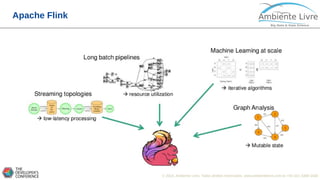
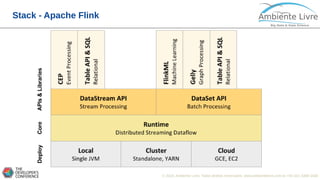
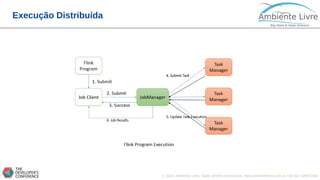
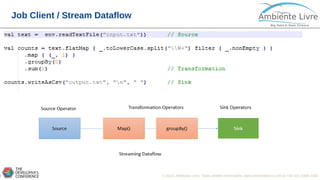
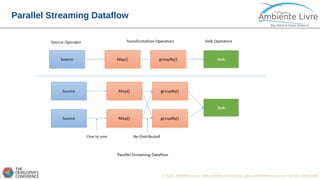
O documento apresenta o Apache Flink, uma plataforma open source para processamento de dados em streaming e em batch. O documento discute as gerações do Big Data, características do Apache Flink como sua arquitetura, operações de streaming e batch, e como se compara com outras ferramentas como o Apache Spark. O documento também mostra exemplos práticos de implementação de aplicações com Apache Flink.




![[DEVFEST] Apache Spark Casos de Uso e Escalabilidade](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark-casosdeusoeescalabilidade-171106111137-thumbnail.jpg?width=640&height=640&fit=bounds)










































