Baixar para ler offline










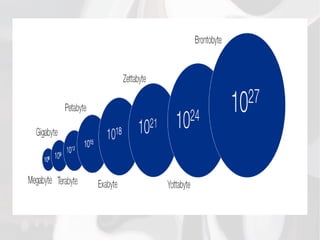









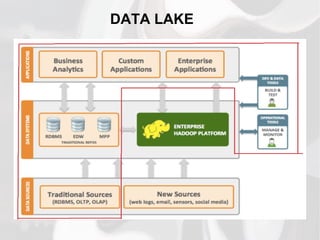


















O documento descreve a evolução dos paradigmas da ciência, desde a ciência empírica há milhares de anos até as simulações complexas e a exploração de dados em grande volume nas últimas décadas. Também discute os desafios do "Big Data" ou grande volume de dados produzidos e a necessidade de iniciar análises a partir de problemas reais.















































