Baixado 22 vezes












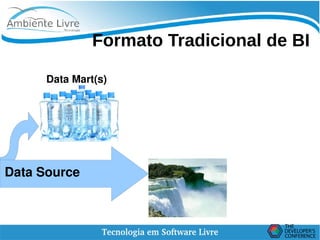
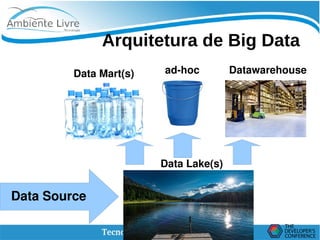


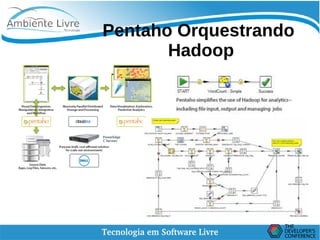
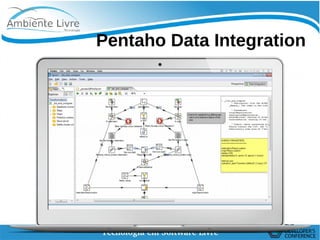

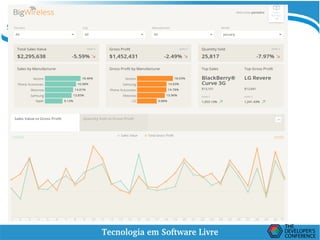
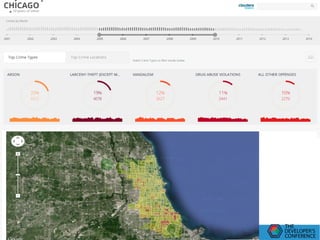



O documento discute conceitos de Data Lakes e como o Pentaho pode ser usado para orquestrar Data Lakes. O Hadoop é apresentado como uma plataforma escalável para armazenar grandes volumes de dados não refinados em Data Lakes. O Pentaho Data Integration pode ser usado para desenvolver frontends com CTools e implementar backends com Hadoop para análise de Big Data.





























































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)












































