Transferir como PDF, PPTX





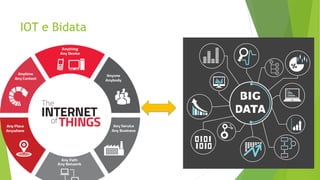
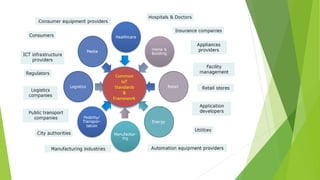
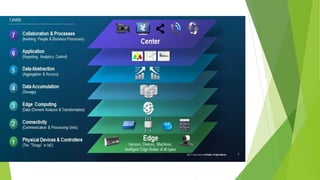
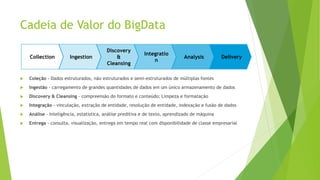











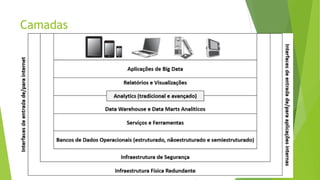

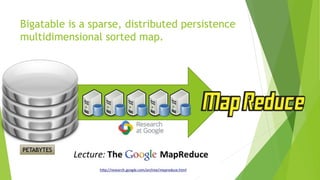

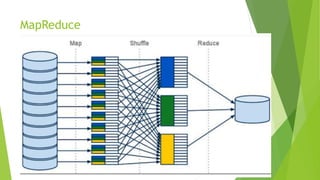


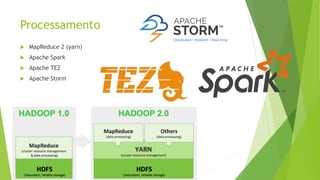



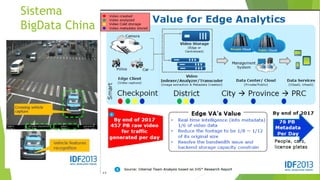









O documento aborda a interseção entre big data e Internet das Coisas (IoT), destacando a coleta, processamento e análise de dados para otimizar a comunicação entre dispositivos conectados. São discutidos conceitos fundamentais, como Hadoop e MapReduce, e aplicações práticas em cidades inteligentes, incluindo monitoramento de tráfego e análise em tempo real. Além disso, o autor oferece diversos cursos de treinamento em tecnologias de big data e ciência de dados.


























![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)




















