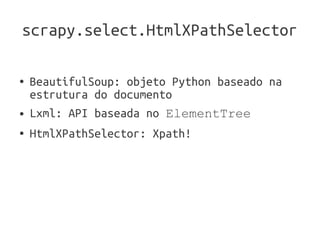
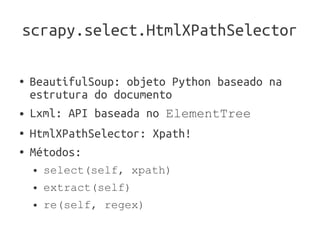
A apresentação introduz o framework Scrapy para construir web crawlers em Python. Ela discute os principais componentes do Scrapy, incluindo Item para modelar dados, Request para fazer requisições, Spider para executar o crawler, e HtmlXPathSelector para selecionar partes da página. A apresentação também menciona outros recursos úteis do Scrapy como Item Pipeline, Scrapy Shell, Feed Exports e integração com Django.