Baixar para ler offline

















![Seletores: CSS vs XPath
CSS
h2
div.classe
#item::text
?
XPath
//h2
.//div[@class="classe"]
.//*[@id="item"]/text()
.//*[@id="item"]/../section](https://image.slidesharecdn.com/webscrapingwithpython-221207041329-0b337e0c/85/Raspagem-de-Dados-com-Python-19-320.jpg)








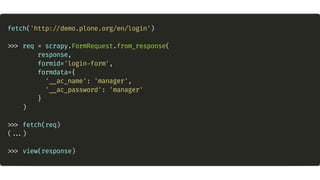

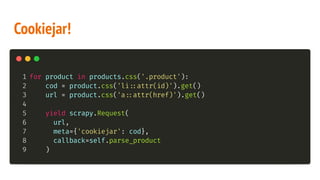





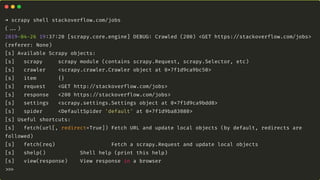
O documento apresenta uma introdução ao web scraping com Python usando o framework Scrapy. Explica que web scraping é a extração automatizada de dados de páginas da web para disponibilização estruturada. Também discute questões legais e técnicas como seletores, spiders e cookies.



























