Baixado 106 vezes


![O que é um Web Crawler?
• Um Web crawler é um programa de
computador que navega pela World Wide
Web de maneira metódica e automatizada.
[Wikipedia]
Também conhecido como web spider, bots e scutter](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-2-320.jpg)



![Googlebot
• Web crawler da Google desenvolvido em C++;
• Utilizado para a descoberta de páginas novas e
atualizadas para serem incluídas no índice da Google;
• Processo de rastreamento de páginas se inicia com
uma lista de URLs, gerada a partir de processos
anteriores, e a cada visita a uma dessas páginas, os
links (SRC e HREF) detectados são incluídos na lista de
páginas a serem atualizadas;
• Novos sites, alterações em sites existentes e links
inativos serão detectados e usados para a atualizar o
índice do Google.
[Google Inc]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-7-320.jpg)
![Scrapy
• Framework open-source implementado em Python
para o desenvolvimento de aplicações de web
crawling;
• Fornece componentes para a seleção e extração de
dados a partir de fontes HTML e XML;
• XPath é utilizado para extrair os dados a partir de
páginas web, onde expressões XPath especificam
tags dos quais serão extraídos os dados;
• Suporte a download automático de imagens
associados com os itens extraídos;
[Insophia, 2007]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-8-320.jpg)
![Nutch
• Web crawler open-source desenvolvido em Java;
• Permite encontrar links de páginas web de forma
automática, verificando links quebrados e criando cópias de todas
as páginas visitadas para pesquisas sobre elas;
• Definição de seeds do crawling em um arquivo de texto com as
URLs, e opcionalmente expressões regulares que especificam
domínio de páginas a serem buscadas;
• Interface por linha de comando para configurar o crawling, setando
parametros como diretório para armazenar o resultado do
crawling, número de threads para busca em paralelo, profundidade
da busca, etc;
• Possui arquitetura bastante modular, permitindo desenvolvedores a
criar plugins para recuperação, consulta e clusterização de dados;
[The Apache Software Foundation, 2004]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-9-320.jpg)

![Crawlers para a web semântica
Arquitetura geral dos crawlers para a Linked
Data:
1. Obter URI da fila
2. Abrir conexão e buscar
conteúdo
3. Processar e armazenar
conteúdo
4. Extrair novos links e
colocar na fila
5. Em intervalos definidos:
escalar URIs na fila
[Andreas Harth, Crawling and Querying Linked Data, 2010]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-12-320.jpg)

![LDSpider
• Web crawler open-source para Linked Data
desenvolvido em Java;
• Busca de arquivos RDF na web de dados a partir de
URIs seed;
• Permite a extração de arquivos em diferentes
formatos, como RDF/XML e N-Quad;
• Fornece tanto uma interface por linha de comando de
fácil utilização, quanto uma API Java que permite
aplicações configurar e controlar os detalhes do
processo de crawling.
[Robert Isele, Andreas Harth, Jürgen Umbrich, and Christian Bizer. 2010]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-14-320.jpg)
![Slug
• Web crawler open-source projetado para extrair conteúdo
da web semântica, implementado em Java usando a API
Jena;
• Fornece um framework modular e configurável que
permite controlar a recuperação, processamento e
armazenamento do conteúdo explorado;
• Recuperação multi-threaded de dados RDF via HTTP e
criação de um cache local de dados extraídos;
• A API Jena permite usar consultas SPARQL para gerar
relatórios a partir da memória do crawler, obtendo
informações como recursos que geraram mais
triplas, histórico de crawl para dado recurso, etc.
[Leigh Dodds, leigh@ldodds.com, February 2006]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-15-320.jpg)
![Ontobroker RDF Crawler
• Web crawler open-source desenvolvido em Java que
permite fazer download de fragmentos interconectados de
RDF – tanto de arquivos RDF puro quanto embutido no
HTML – da web de dados;
• Manutenção de uma lista de URIs para serem recuperadas
durante o crawling;
• Filtragem de URIs através da especificação de domínios, de
prefixo da URI, por extensão de arquivos
(HTML, RDF, etc.), entre outras;
• Assim como o LDSpider, é fornecida uma aplicação console
e uma API embutida que permite o desenvolvimento de
novas aplicações de crawling.
[Kalvis Apsitis, kalvis.apsitis@dati.lv, DATI Software Group, 2000]](https://image.slidesharecdn.com/meeting16-09-11-att-111023103541-phpapp01/85/Web-Crawlers-16-320.jpg)

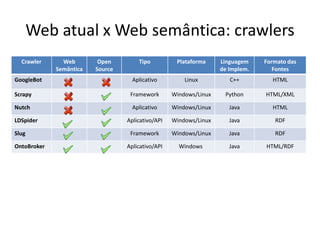

1) Um web crawler é um programa que navega automaticamente pela web coletando informações de páginas como links, tags e palavras-chaves. 2) Crawlers para a web semântica coletam dados em formatos como RDF usando relacionamentos como rdfs:seeAlso ao invés de apenas hiperlinks HTML. 3) Exemplos de crawlers para a web atual incluem Googlebot, Scrapy e Nutch, enquanto LDSpider, Slug e OntoBroker são para a web semântica.




































