Transferir como PDF, PPTX



![Curiosidades - Google (1998)
urls = [‘siteA.com’] #seed / sementes
foreach(urls as url){
requisicaoGET(siteA.com)
extrai(“<a href=’http://siteB.com’>link B</a>”)
requisicaoGET(‘siteB.com’)
extrai(“<a href=’http://siteC.com’>link C</a>”)
requisicaoGET(‘siteC.com’)
… e assim vai ...
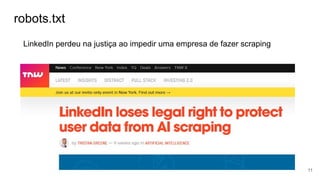
Basicamente temos um esquema de GRAFOS.
Bread First Search - Busca em Largura
Deep First Search - Busca em Profundidade
5
- O primeiro crawling foi feito em 1993
- Google não é pioneiro - 1994 https://en.wikipedia.org/wiki/World-Wide_Web_Worm](https://image.slidesharecdn.com/coletadedados-171207053942/85/Crawling-Coleta-de-dados-na-Web-com-PHP-5-320.jpg)








![Timeout - CLI (Command Line Interface)
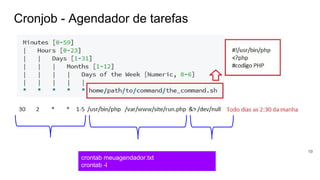
$_ = $_SERVER['_']; (Retorna o binário /usr/bin/php)
$restartMyself = function () {
global $_, $argv;
pcntl_exec($_, $argv);
};
register_shutdown_function($restartMyself);
set_error_handler($restartMyself , E_ALL);
Este codigo faz o script PHP rodar o
tempo todo, mesmo que finalize o loop
do BD ou se der erros.
20](https://image.slidesharecdn.com/coletadedados-171207053942/85/Crawling-Coleta-de-dados-na-Web-com-PHP-20-320.jpg)


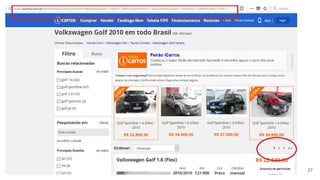



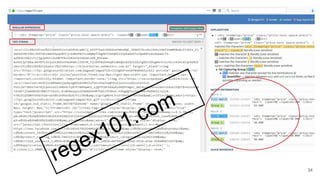
![listagem
PSEUDOCODIGO
$urls =
[
‘icarros’=>’www.icarros.com.br/busca.blabla…&tag=golf’,
‘webm’=>‘www.webmotors.com.br/busca…tag2=golf’
];
foreach($urls as $key=>$url){
$html = crawling($url, $key);
$paginas = getInfoNumPaginas($html) ?? 0;
for($i=2; $i<=paginas;$i++){
crawling($site.’&pag=’.$i)
}
}
function crawling(string $url): string{
#varias opcoes
$html = file_get_contents($url)
$pag=explode(‘&’,$url)[‘pag’];
parseAndSave2BD($html,$url,$pag);
return $html
}
function parseAndSave2BD(string $html, $url, $pag=1): bool{
#aqui usamos Regex para extrair total e salvar tabela listagem
$q = “insert listagem set
url=’$url’,total=$total,pag=$pag
on duplicate key update
}
function getInfoNumPaginas($html): int{
return preg_match(‘/<li>(.+?)</li>/’,$html,$matches) ?? 0;
}
36](https://image.slidesharecdn.com/coletadedados-171207053942/85/Crawling-Coleta-de-dados-na-Web-com-PHP-36-320.jpg)

![detalhes
PSEUDOCODIGO
$ids = $cn->query(“select id from detalhes where parsed=0”);
foreach($ids as $id){
$html = crawling($url . $id)
$arrayInfo = getInfoViaRegex($html)
$arrayInfo = getInfoViaDOM($html)
saveData2BD($arrayInfo)
}
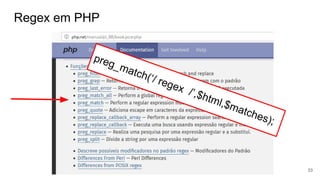
function getInfoViaRegex($html){
$preco = preg_match(‘/<td><a>(.+)</a></td>/’,$html);
$ano = preg_match(‘/<td><a>(.+)</a></td>/’,$html);
return [‘preco’=>$preco,’ano’=>$ano];
}
function getInfoViaDOM($html){
$dom = new DOMDocument();
$dom->loadHTML($html);
foreach($dom->getElementsByTagName(‘a’) as $link){
if($link->getAttribute(‘class’)==’preco’){
$preco = $link->item(0)->nodeValue;
}
}
...
return [‘preco’=>$preco,’ano’=>$ano];
}
function saveData2BD($arrayInfo){
global $cn; extract($arrayInfo);
$q=”update detalhes set parsed=1,campo2=$campo2”;
return $cn->exec($q);
} 38](https://image.slidesharecdn.com/coletadedados-171207053942/85/Crawling-Coleta-de-dados-na-Web-com-PHP-38-320.jpg)
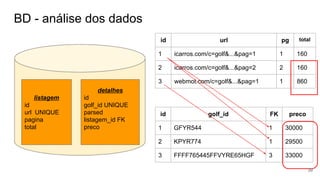




O documento apresenta um resumo sobre coleta de dados na web (web crawling e scraping) utilizando PHP. Aborda definições, principais pontos como robots.txt e headers, além de apresentar pseudocódigos para listagem de páginas e extração de detalhes, com armazenamento em banco de dados MySQL.



































