Baixado 57 vezes





![Buscas
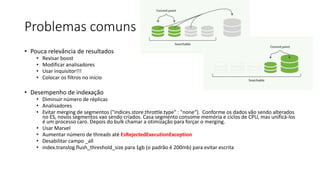
• Fields
• Fuziness
• Ordenação
• Paginação
• Boost
• Agregações
• Suggestions
POST /indice/post/_search
{
"fields" : "descricao",
"from" : 0, "size" : 10,
"sort" : [
"_score",
“data",
“relator"
],
"query": {
"filtered": {
"query": {
"match": {](https://image.slidesharecdn.com/elasticsearch-parte2-vfinal-150425233204-conversion-gate01/85/Treinamento-Elasticsearch-Parte-2-6-320.jpg)




![Sort
POST /indice/post/_search
{
"fields" : "descricao",
"from" : 0, "size" : 10,
"sort" : [
"_score",
“data",
“relator"
],](https://image.slidesharecdn.com/elasticsearch-parte2-vfinal-150425233204-conversion-gate01/85/Treinamento-Elasticsearch-Parte-2-11-320.jpg)
![Boost
"must": [
{
"prefix": {
"relator": "ANTONIO",
"boost": "500"
}
}
],](https://image.slidesharecdn.com/elasticsearch-parte2-vfinal-150425233204-conversion-gate01/85/Treinamento-Elasticsearch-Parte-2-12-320.jpg)










O documento apresenta uma introdução aos conceitos avançados do Elasticsearch, incluindo: (1) buscas filtered para combinar consultas e filtros, (2) multifields para indexação e busca em campos diferentes, e (3) agregações para resumir resultados de buscas agrupados por campos.



































































