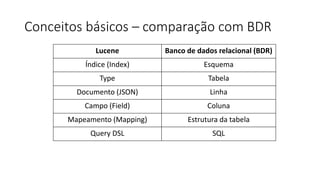
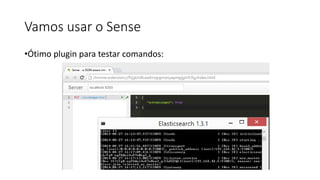
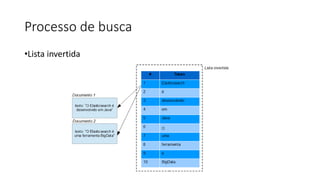
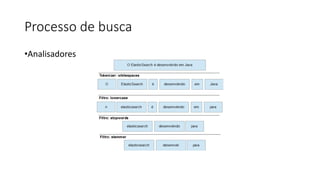
Baixado 100 vezes










![Criar um índice
•Forma mais simples:
•PUT /goodname
•Podemos também adicionar configurações na criação desse índice:
PUT / goodname/{
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"sinonimo": {
"tokenizer": "whitespace",
"filter": [ "lowercase", "filtro_sinonimo"]
},
...](https://image.slidesharecdn.com/elasticsearch-parte1-vfinal-150424155045-conversion-gate01/85/Treinamento-Elasticsearch-Parte-1-13-320.jpg)





![Buscas - Multi match
POST /goodname/processo/_search
{
"query": {
"multi_match": {
"query": "carro",
"fields": [
"descricao",
"palavrachave"
]
}
}](https://image.slidesharecdn.com/elasticsearch-parte1-vfinal-150424155045-conversion-gate01/85/Treinamento-Elasticsearch-Parte-1-21-320.jpg)



![Buscas - Bool
POST /goodname/processo/_search
{
"query": {
"bool": {
"must": [
{}
],
"should": [
{}
],
"must_not": [](https://image.slidesharecdn.com/elasticsearch-parte1-vfinal-150424155045-conversion-gate01/85/Treinamento-Elasticsearch-Parte-1-25-320.jpg)








![Plugins
•Site plugins
•HEAD
•http://localhost:9200/_plugin/head/
•plugin -install mobz/elasticsearch-head
•BigDesk
•http://localhost:9200/_plugin/bigdesk/
•plugin -install lukas-vlcek/bigdesk
•Inquisitor
•https://github.com/polyfractal/elasticsearch-inquisitor
•plugin -install polyfractal/elasticsearch-inquisitor
•plugin --url file:///c:/tmp/elasticsearch-inquisitor-master.zip --install inquisitor
•Synonyms
•Na inicialização de cada nó:
•[2015-01-14 08:54:33,515][INFO ][plugins ] [Seth] loaded [analysis-
phonetic], sites [bigdesk, head, inquisitor]](https://image.slidesharecdn.com/elasticsearch-parte1-vfinal-150424155045-conversion-gate01/85/Treinamento-Elasticsearch-Parte-1-35-320.jpg)

![Instalação
•cluster.name: agoodname
•node.name: "anothergoodname"
•discovery.zen.ping.multicast.enabled: false
•discovery.zen.ping.unicast.hosts: ["10.0.0.201", "10.0.0.202",
"10.0.0.203"]
•bootstrap.mlockall: true
•script.disable_dynamic: false](https://image.slidesharecdn.com/elasticsearch-parte1-vfinal-150424155045-conversion-gate01/85/Treinamento-Elasticsearch-Parte-1-37-320.jpg)






Este documento apresenta uma introdução ao Elasticsearch, cobrindo sua visão, histórico, conceitos-chave, instalação, buscas, clientes, arquitetura e considerações sobre desempenho. É dado ênfase aos processos de indexação, busca, clientes Java e arquitetura distribuída do Elasticsearch.









































































