Baixado 91 vezes






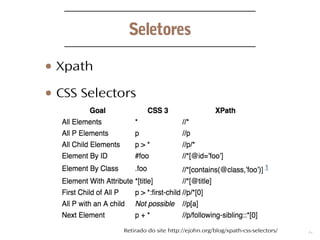



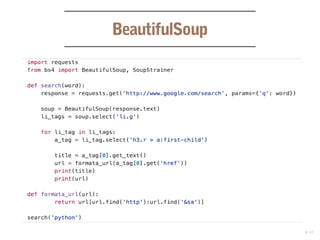


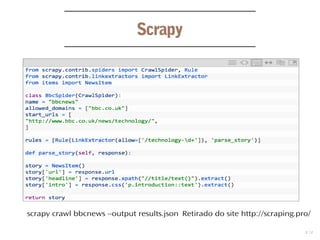



O documento discute o desenvolvimento de web crawlers e scrapers em Python, explicando suas principais funções como coleta de hyperlinks e extração de informações. Apresenta várias bibliotecas e frameworks, como lxml e Scrapy, utilizados para manipulação de dados e suporte a seletores CSS e XPath. Além disso, menciona formatos de saída para os dados extraídos, como JSON, CSV e XML.
































































