Baixado 51 vezes
























![Testando
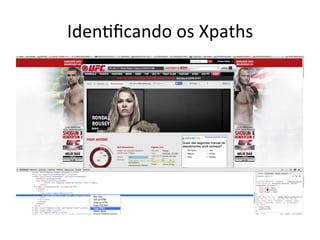
Xpaths
• $
scrapy
shell
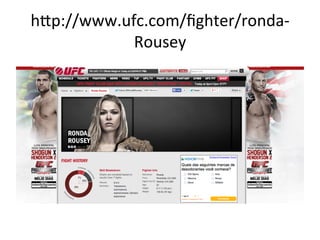
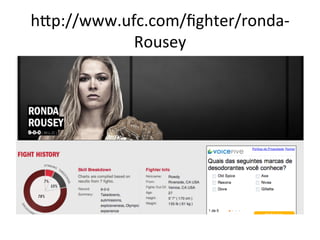
hEp://www.ufc.com/fighter/ronda-‐Rousey
– $
sel.xpath('//div[@id="fighter-‐breadcrumb"]/
span/h1/text()').extract()
– [u'Ronda
Rousey']](https://image.slidesharecdn.com/capturando-a-web-com-scrapy-140407203755-phpapp02/85/Capturando-a-web-com-Scrapy-28-320.jpg)








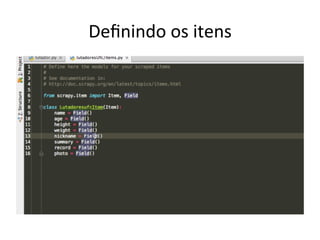
O documento descreve como usar a biblioteca Scrapy em Python para criar um web crawler. Ele explica o que é um web crawler, sua estrutura básica e como Scrapy resolve problemas comuns como autenticação, sessões, requisições simultâneas e persistência de dados. Em seguida, guia o leitor passo a passo na criação de um crawler para extrair informações de lutadores do site UFC.com.




































![OpenData-BR, [Captando] Dados públicos brasileiros](https://cdn.slidesharecdn.com/ss_thumbnails/opendatabr-rc2-110119072252-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























