Baixado 74 vezes















![Filtros
filter {
csv {
columns =>
["datahora","ordem","linha","latitude","longitude","velocidade"]
separator => ","
}
date {
match => ["datahora","MM-dd-YYYY HH:mm:ss"]
locale => "br"
target => "@timestamp"
}
...
}](https://image.slidesharecdn.com/elasticsearch-comogerenciarseuslogscomlogstashekibana-v5-vfinal-150722234545-lva1-app6892/85/Elasticsearch-como-gerenciar-seus-logs-com-logstash-e-kibana-24-320.jpg)
![Filtros
filter {
...
if [velocidade]=="0" {
drop{}
}
mutate {
convert => [ "velocidade", "float" ]
}
...
}](https://image.slidesharecdn.com/elasticsearch-comogerenciarseuslogscomlogstashekibana-v5-vfinal-150722234545-lva1-app6892/85/Elasticsearch-como-gerenciar-seus-logs-com-logstash-e-kibana-25-320.jpg)
![Filtros
filter {
...
if [latitude] and [longitude] {
mutate {
add_field => [ "[location]", "%{longitude}" ]
add_field => [ "[location]", "%{latitude}" ]
}
mutate {
convert => [ "[location]", "float" ]
}
}
...
}](https://image.slidesharecdn.com/elasticsearch-comogerenciarseuslogscomlogstashekibana-v5-vfinal-150722234545-lva1-app6892/85/Elasticsearch-como-gerenciar-seus-logs-com-logstash-e-kibana-26-320.jpg)

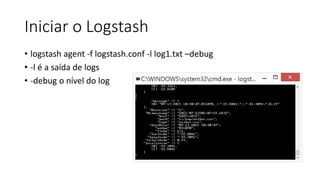
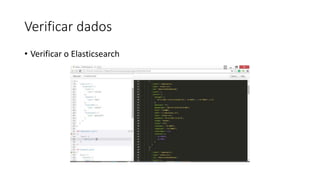



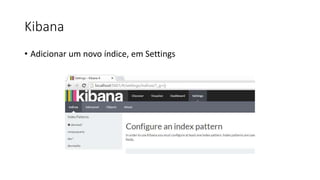
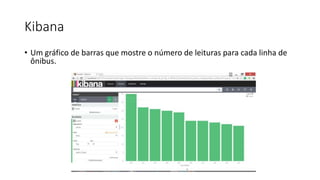
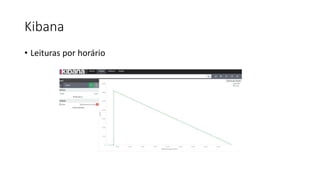
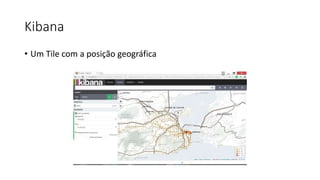
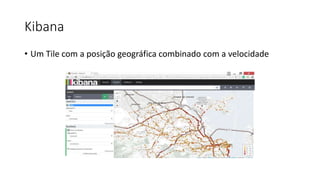
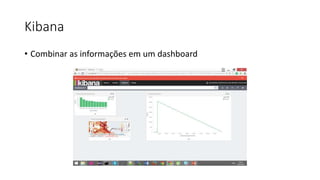


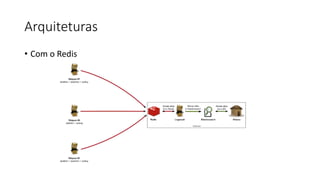
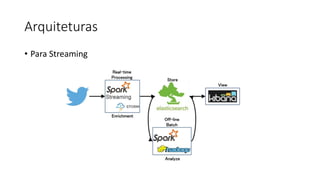
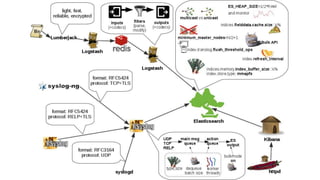
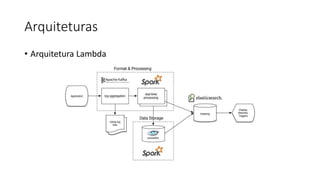





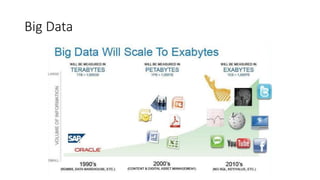
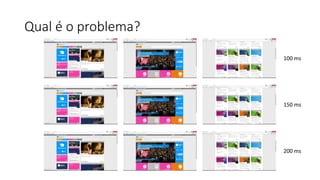
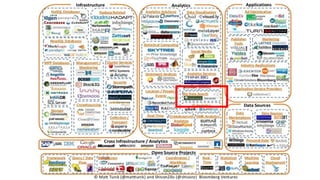
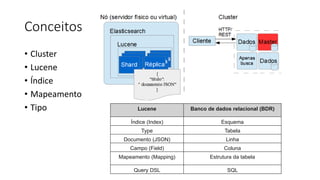
Este documento resume uma apresentação sobre Elasticsearch, Logstash e Kibana. A apresentação introduz estas ferramentas de gerenciamento de logs e dados, explica como configurar um pipeline ELK para indexar e visualizar logs de ônibus do Rio de Janeiro, e discute possíveis arquiteturas e usos futuros destas ferramentas.



































































