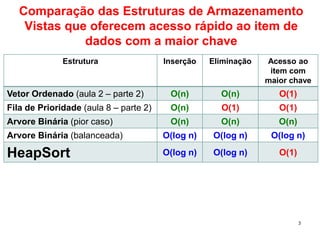
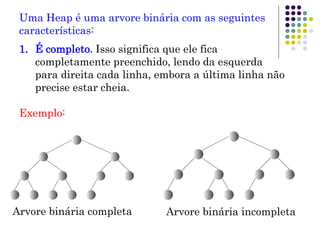
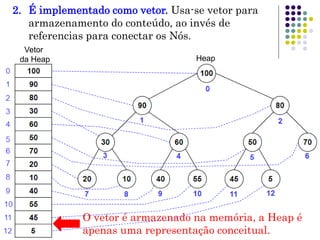
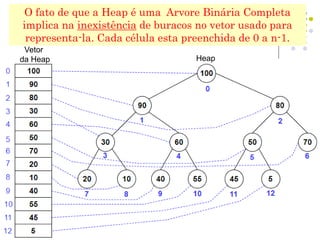
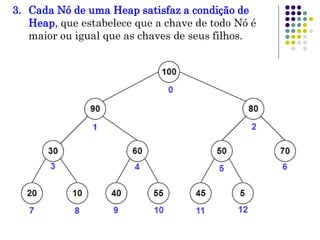
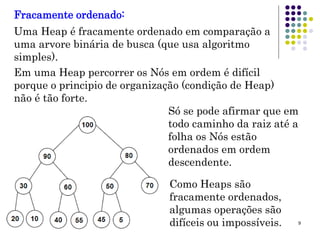
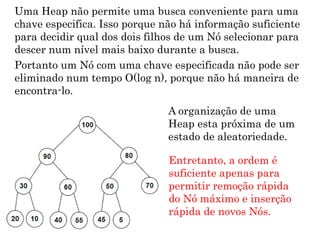
O documento descreve o que é uma heap, como é sua estrutura e operações básicas de inserção e remoção. Uma heap é uma árvore binária balanceada que oferece acesso rápido ao item com a maior chave. Inserção e remoção ocorrem em tempo O(log n) através de movimentação de nós para cima ou para baixo na árvore.




![11
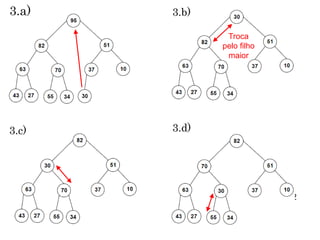
Remoção significa remover um Nó com a chave
máxima. Esse Nó é sempre a raiz e ela esta no índice
zero do vetor da Heap, portanto remove-lo é fácil.
Remoção
O problema é que restara um “buraco” que tem de ser
preenchido. Para isso usa-se os seguintes passos:
1. Remova a raiz
2. Mova o ultimo Nó para raiz
vHeap[0] = vHeap[n-1];
n--;
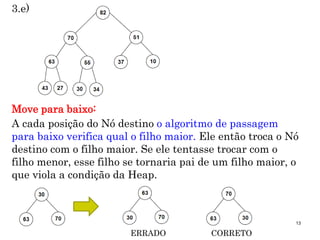
3. Passe para baixo o ultimo Nó até que ele fique abaixo de
um Nó maior e acima de um Nó menor.](https://image.slidesharecdn.com/aula14-p1-ed-heaps-171207164853/85/Aula-20-11-320.jpg)
![14
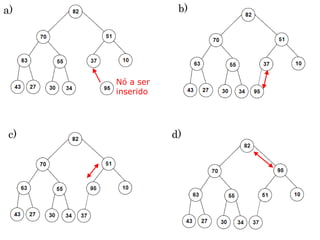
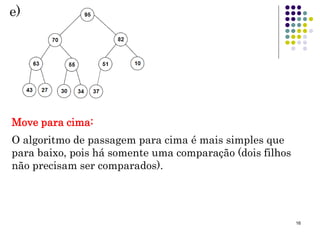
A inserção usa passagem para cima, ao invés de para
baixo. Inicialmente o Nó a ser inserido é colocado na
primeira posição aberta no final do vetor.
Inserção
vHeap[n] = novo;
n++;
Logo após, caso se faça necessário para se manter a
condição de Heap, o novo Nó será passado para cima até
que fique abaixo de um Nó com uma chave maior e acima
de um Nó com uma chave menor.](https://image.slidesharecdn.com/aula14-p1-ed-heaps-171207164853/85/Aula-20-14-320.jpg)