Baixado 190 vezes










![Ordenação por Seleção - Código
SelectionSort(A)
1 n <- tamanho[A]
2 para I <- 1 até N-1 faça
3 J <- indiceDoMenorValor (A,i,n)
4 troque A[i] com A[J]
5 // A[1..i] os menores números (1 até i) em ordem
6 fim para;
7 fim procedimento](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-14-320.jpg)

![Bubble Sort (método da bolha)
Princípio:
● As chaves Item[1].Chave e Item[2].Chave são comparadas e
trocadas se estiverem fora de ordem;
● Repete-se o processo de comparação e troca com Item[2] e
Item[3], Item[3] e Item[4], ...
Por que Bolha?
Se o vetor a ser ordenado for colocado na vertical, com Item[n] em
cima e Item[1] embaixo, durante cada passo o menor elemento
“sobe” até encontrar um elemento maior ainda, como se uma
bolha subisse dentro de um tubo de acordo com sua densidade](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-16-320.jpg)
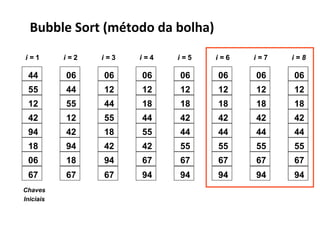


![Bubble Sort (método da bolha)
BubbleSort(A)
1 n <- tamanho[A]
2 para I <- 1 até N faça
3 Para J <- N até i-1 faça {contador decrescente}
4 Se A[J] < A[J-1] então
5 troque A[i] com A[J]
6 fim se
7 fim para;
8 fim procedimento](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-20-320.jpg)


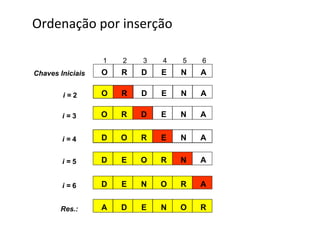




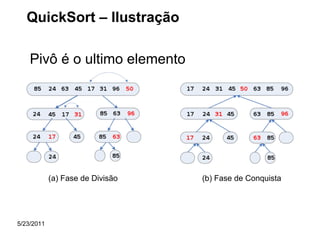
![QuickSort – Esquema conceitual
Inicialmente, o vetor C é particionado em três segmentos S1, S2 e S3.
● S2 deverá conter apenas UMA chave denominada pivô.
● S1 deverá conter todas as chaves cujos valores são MENORES ou
IGUAIS ao pivô. Esse segmento está posicionado à esquerda de S2.
● S3 deverá conter todas as chaves cujos valores são MAIORES do que
o pivô. Esse segmento está posicionado à direita de S2.
Vetor Inicial : C [ 1 .. n ]
n
1
Vetor Particionado
1
k-1
S1
k
n
k+1
S2
onde: C [ i ] <= C [ k ] , para i = 1, … , k - 1
C [ i ] > C [ k ] , para i = k + 1 , … , n
S3](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-30-320.jpg)


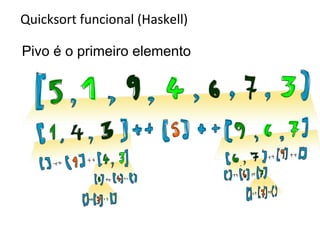
![Quicksort funcional (Haskell)
qs [] = []
qs (x:xs) = qs [y | y <- xs, y < x]
++ [x]
++ qs [y | y <- xs, y >= x]
É o quicksort aplicado a
todos elemente menores
que o pivó X
Concatenada (++), com o
pivó X
Concatenado com o
quicksort aplicado a todos
elementos maiores que o
pivó X](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-34-320.jpg)
![Quicksort - Imperativo
1) Escolha do pivô (p);
2) Processo de comparações:
Compara v[1], v[2], ... até encontrar um elemento v[a]>p, onde v é o vetor de chaves.
Compara, a partir do final do vetor, os elementos v[n-1],v[n-2], ... Até encontrar v[b]<=p.
3) Neste ponto, troca-se v[a] e v[b], e a busca continua, para cima a partir de v[a+1], e
para baixo, a partir de v[b-1];
4) A busca termina, quando os pontos (a e b) se cruzarem. Neste momento, a posição
definitiva de p foi encontrada, e os valores de p e v[b] são trocados;
5) O particionamento é realizado até os segmentos resultantes tiveram comprimento > 1.
Fonte: Prof. Alexandre Parra Carneiro da Silva:http://www.joinville.udesc.
br/portal/professores/parra/materiais/cap10_quicksort.pp](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-36-320.jpg)


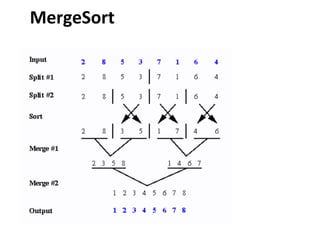
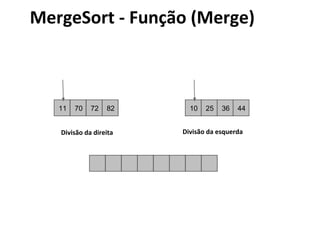
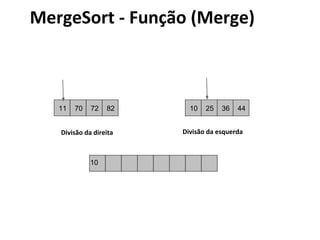
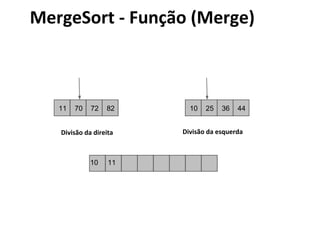
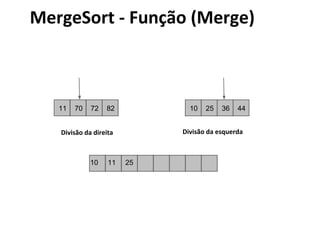
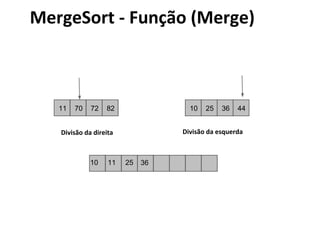
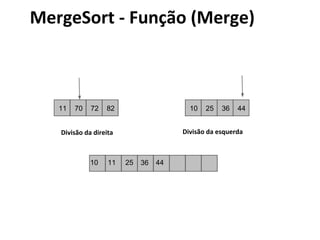
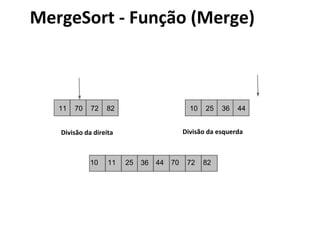
![MergeSort - Algoritmo
void mergesort(int array[], int i, int f) {
if (i < f) {
int mid = (i+f)/2;
mergesort (array, i, mid);
mergesort (array, mid+1, f);
intercala (array, i, mid, f);
}](https://image.slidesharecdn.com/ordenacao-140127155218-phpapp02/85/Ordenacao-47-320.jpg)


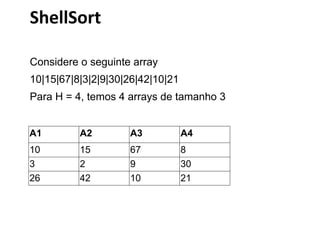
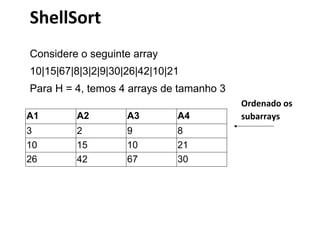






1) O documento apresenta uma introdução sobre ordenação em JQuery e AJAX, incluindo métodos de ordenação como seleção, inserção e bolha. 2) São descritos conceitos como ordenação interna, externa e local, além de análises de eficiência dos algoritmos. 3) Métodos simples como seleção, inserção e bolha são comparados a métodos eficientes como quicksort e mergesort.























































































