Transferir como PDF, PPTX















![Apache Spark
● Exercícios
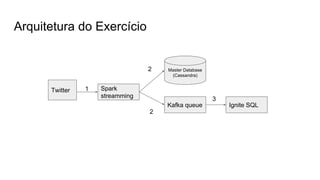
○ Usando como base o código de streaming do Twitter, salvar as informações no Cassandra.
● Desafio
○ Usar o conector para Kafka para receber os dados de Produtos e Vendas do exercício
anterior via s]treaming.](https://image.slidesharecdn.com/neoway-final2-160824202627/85/Processamento-em-Big-Data-39-320.jpg)




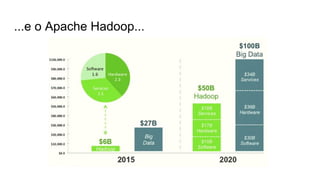
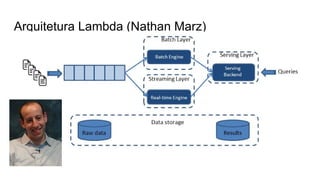
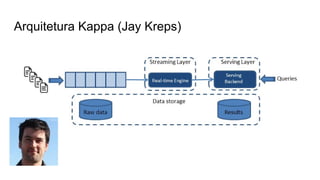
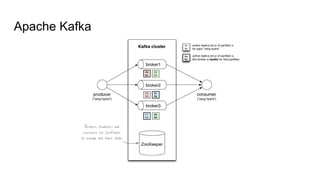
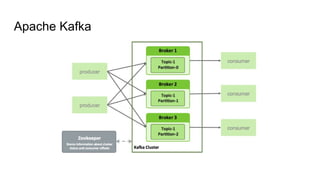
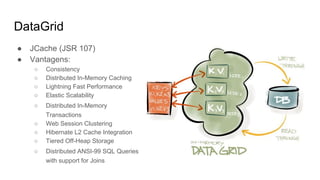
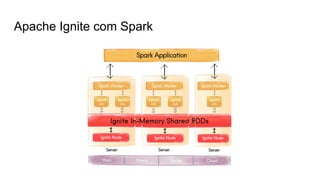
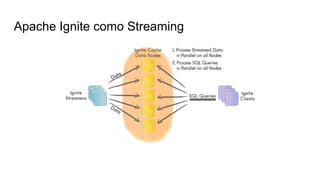
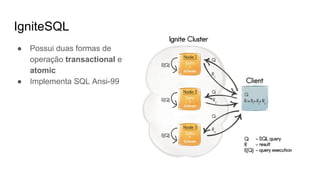
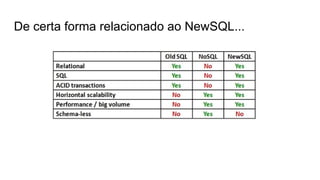
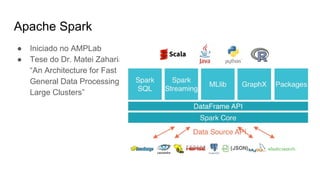
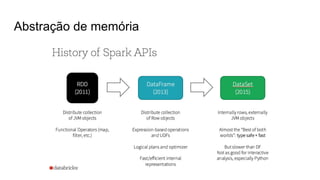
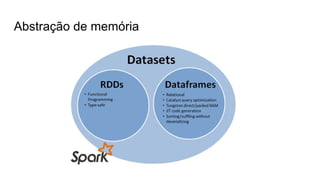
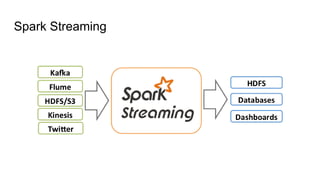
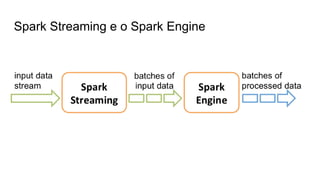
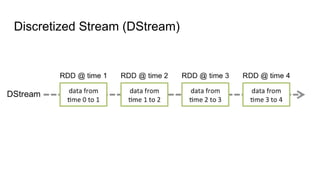
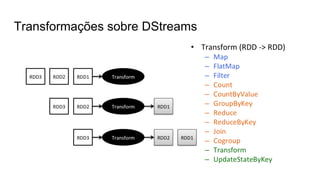
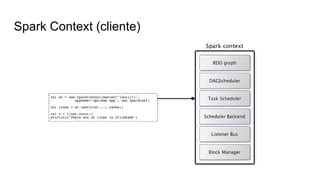
O documento discute várias tecnologias para processamento de big data, incluindo MapReduce, Hadoop, Apache Kafka, Apache Ignite, e Apache Spark. Ele fornece exemplos de código e exercícios para cada tecnologia e conclui discutindo outras opções como Apache Parquet e Apache Mesos.












![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DEVFEST] Apache Spark Casos de Uso e Escalabilidade](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark-casosdeusoeescalabilidade-171106111137-thumbnail.jpg?width=640&height=640&fit=bounds)





















