Transferir como PDF, PPTX





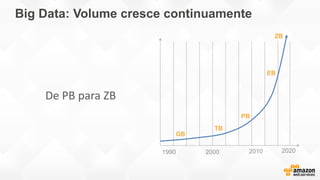


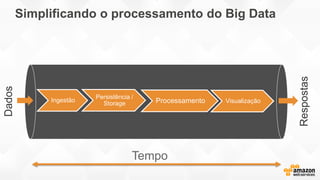
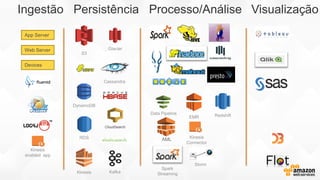

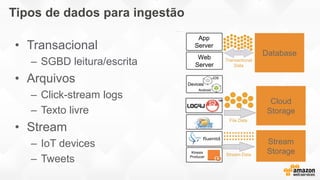
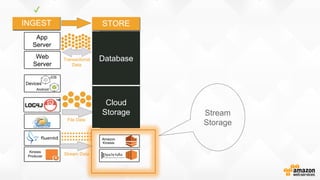


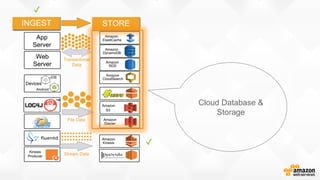

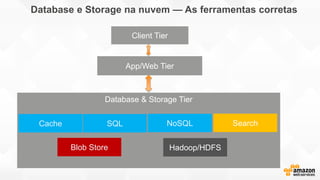
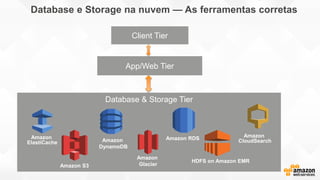

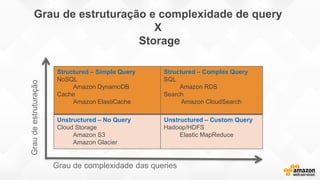
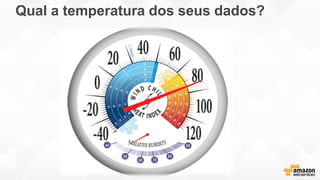

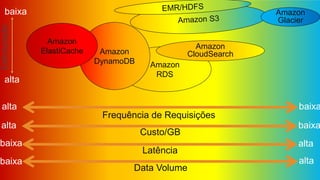
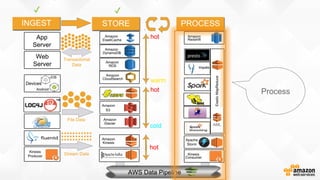



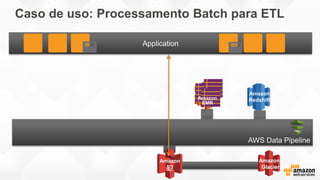

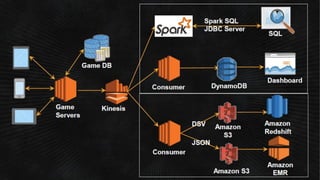
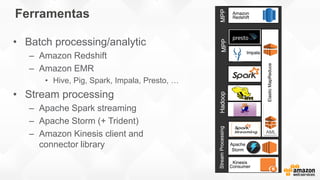

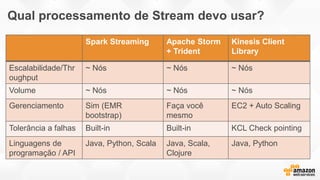
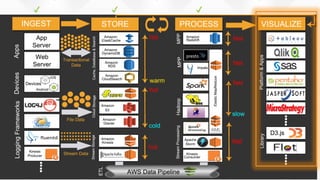

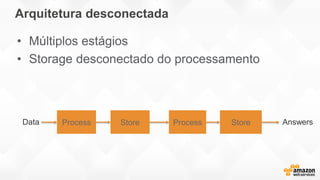
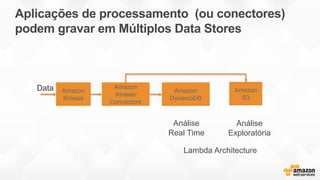
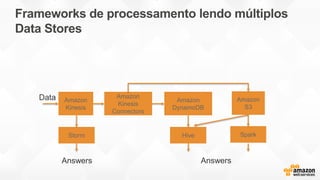

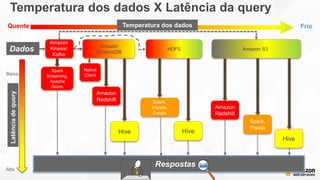
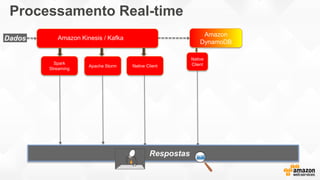
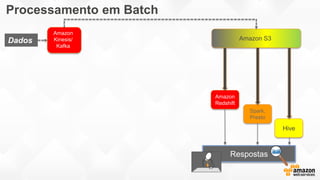
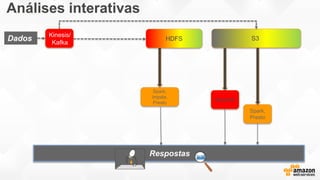
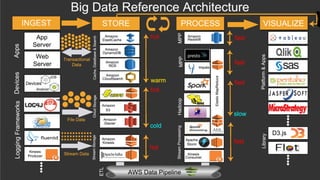



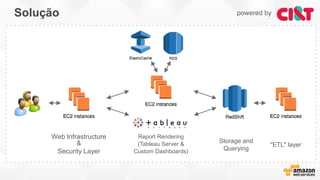



- O documento discute os desafios e soluções de arquitetura para projetos de Big Data, incluindo ingestão, armazenamento, processamento e visualização de dados. - É apresentada uma visão simplificada do fluxo de processamento de Big Data e quais tecnologias usar de acordo com o tipo e temperatura dos dados. - São discutidos padrões de arquitetura e design patterns para integrar as diferentes ferramentas de forma desconectada e escalável.



![[Webinar] AWS Storage Day - Português](https://cdn.slidesharecdn.com/ss_thumbnails/storageday-15052018pt-180518151634-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)






























