Baixar para ler offline




![A APLICAÇÃO SPARK
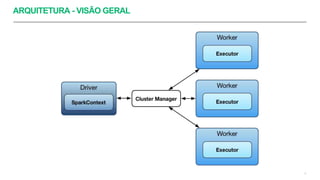
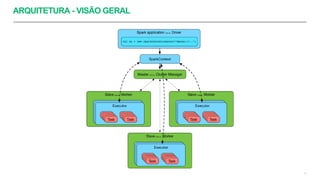
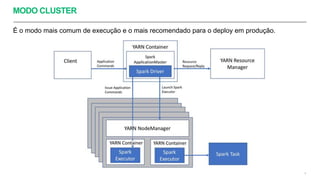
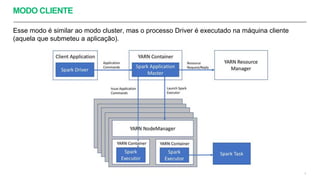
Uma aplicação Spark é composta (logicamente) por um processo Driver e vários processos
Executors.
Geralmente o utilizamos o seguinte comando para submeter uma aplicação Spark num cluster
Yarn:
sudo spark-submit --class com.thoughtworks.core.JobsExample --master yarn --deploy-mode
cluster s3://com.thoughtworks.training.de.recife/facilitador/de-training-0.1-SNAPSHOT.jar arg1
arg2
Ou o seguinte comando quando quero utilizar a API do AWS EMR:
aws emr add-steps --cluster-id j-2AXXXXXXGAPLF --steps Type=Spark,Name="Spark
Program”,ActionOnFailure=CONTINUE,Args=[--
class,org.apache.spark.examples.SparkPi,/usr/lib/spark/lib/spark-examples.jar,arg1,arg2]
11](https://image.slidesharecdn.com/apachesparkintro-200721143332/85/Apache-spark-intro-11-320.jpg)









![STRUCTURED API - DATASET
31
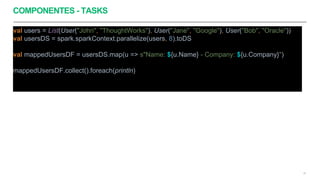
usersParquetDS.map(_.Name).as[User]
.filter(_.Company == "ThoughtWorks")](https://image.slidesharecdn.com/apachesparkintro-200721143332/85/Apache-spark-intro-31-320.jpg)
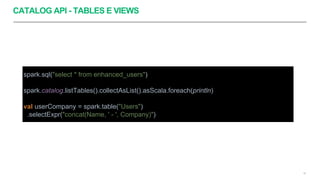

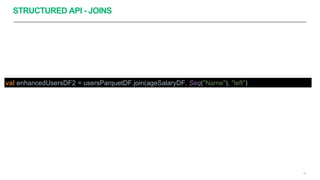
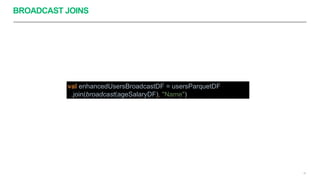



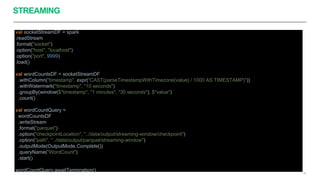
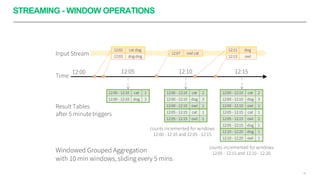
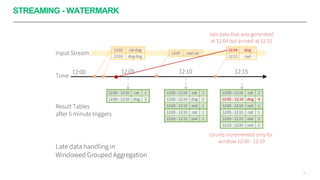




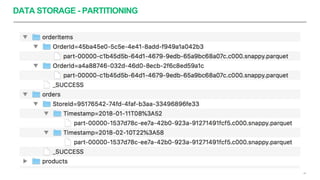








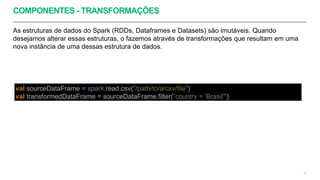
Apache Spark é um framework para processamento de dados distribuído que suporta processamento em lote e em streaming. Ele possui APIs para manipulação de dados estruturados e não estruturados de forma paralela em clusters. Apache Spark também fornece ferramentas para armazenamento, recuperação e análise de grandes volumes de dados.


























![[Datafest 2018] Apache Spark Structured Stream - Moedor de dados em tempo qua...](https://cdn.slidesharecdn.com/ss_thumbnails/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DEVFEST] Apache Spark Casos de Uso e Escalabilidade](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark-casosdeusoeescalabilidade-171106111137-thumbnail.jpg?width=640&height=640&fit=bounds)










