Baixar para ler offline





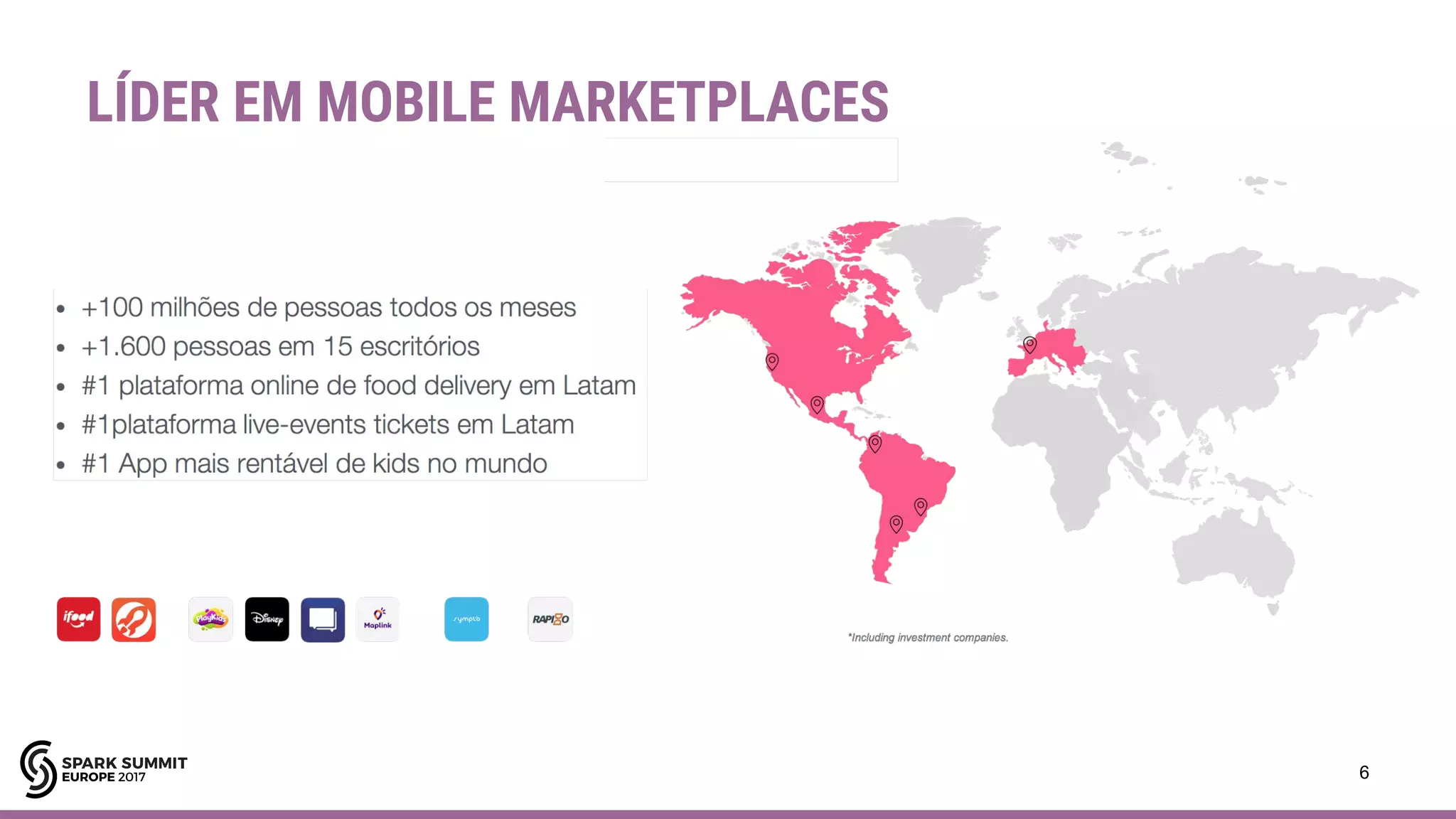





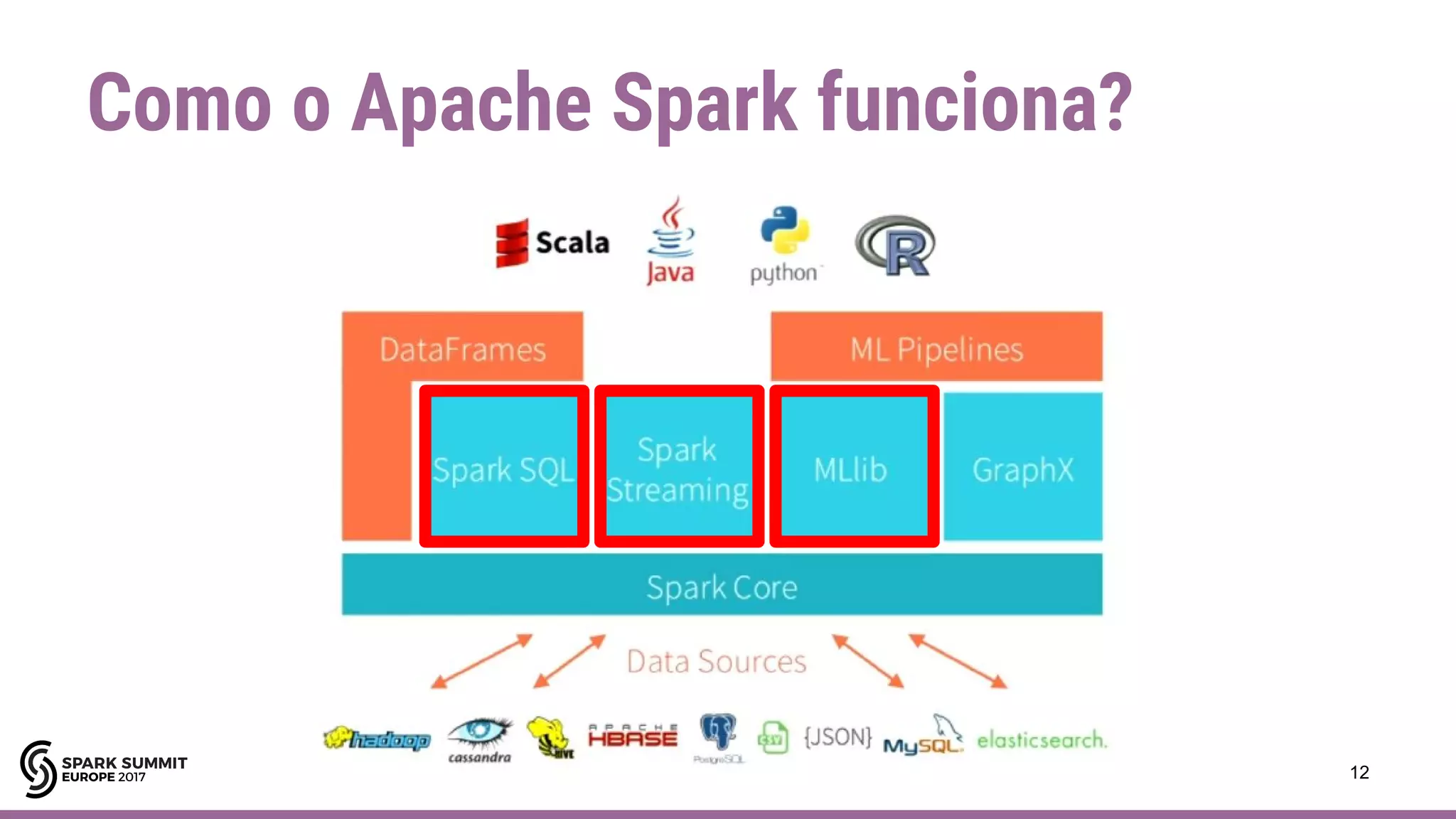

















Apache Spark é um framework para processamento de dados em larga escala. Ele funciona armazenando dados em memória para processamento paralelo rápido. O documento descreve casos de uso do Spark, incluindo SQL, streaming, machine learning e considerações sobre limitações.






![[Datafest 2018] Apache Spark Structured Stream - Moedor de dados em tempo qua...](https://cdn.slidesharecdn.com/ss_thumbnails/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)




































